- 비동기 백엔드 아키텍쳐 설계2024년 03월 17일 15시 11분 19초에 업로드 된 글입니다.작성자: 재형이반응형
1. API Server
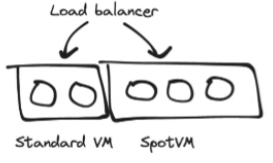
- API Server는 보통 세션 정보나 API 키는 중간에 Redis에 넣기 때문에 Stateless 하다. 그래서 api 서버가 restart된다고 큰 문제가 발생하지 않는다
- 그래서 AWS 클라우드 환경에서 API 서버를 2:8의 비율로 standard와 spot 인스턴스를 조합해서 구성하면 비용을 크게 절감할 수 있다
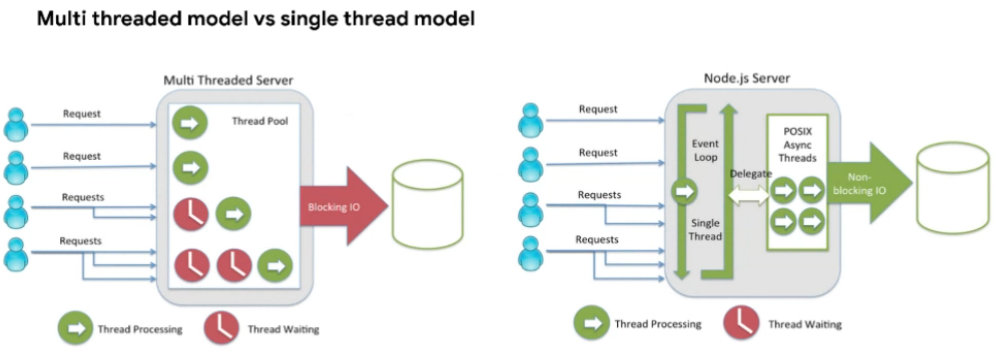
- Multi Threaded Model은 쓰레드 수만큼 처리를 할 수 있다. 자바는 Multi Thread이다
- 그래서 C10K (Concurrent 10K users,동시 사용자 만명)를 하려면 자바에서는 보통 쓰레드 수를 100개 많으면 500개 두기 때문에 서버 수가 100개가 있어야 한다 → 너무 리소스가 많이 든다
- 그래서 나온 것이 Non-blocking I/O 이다
- Single Thread가 돌다가 request가 들어오면 response를 안 기다리고 다시 다른 request를 처리한다. 그러다가 response가 오면 그걸 처리함 → 하나의 쓰레드로도 많은 수의 동시 커넥션을 처리할 수 있음
cf) 각 쓰레드가 ulti thread는 request 처리를 하고 response를 기다림. 그래서 쓰레드 수만큼만 동시 처리할 수 있음 - 정리 :
- Multi Thread : 동접자 수가 쓰레드 수만큼 밖에 안되지만, CPU를 많이 사용하는 시스템이 적합
- Single Thread : Socket I/O던지 API 라던지 가볍게 가면서 많은 동접자 수를 가져가기에 적합
API Server 구성하기
- 애플리케이션 서버 결정
- Multi Threaded Model
- Single Threaded Model
- 서버를 올릴 인프라 결정
- VM
- Container (K8S)
- Serverless
2. Cache
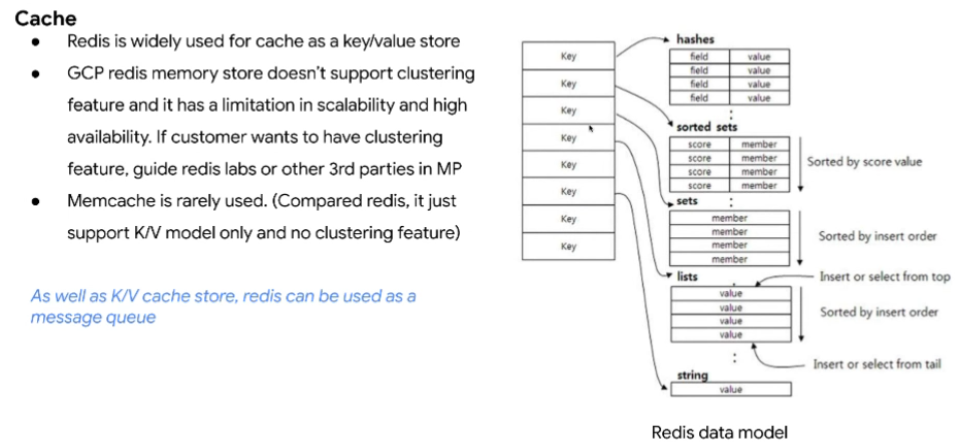
- Cache는 Redis로 다 넘어가는 추세이다
- Redis에는 단순히 Key-Value 구조로 할 수도 있지만 이런것 뿐만 아니라 Value 안에다가 Hash Table, Sorted Set 등 여러가지를 넣을 수 있다
- 예를 들어 Key-Sets 구조로 단순히 API 키뿐만 아니라 여러가지 정보들을 같이 저장할 수 있다
- Memcached는 Key-Value만 지원한다
- Redis는 Key-Value Store 기능 외에도 메시징 큐 기능을 할 수 있어서 사용 용도가 다양하다
- Redis도 Single Treaded Model을 사용한다. CPU를 아무리 많이 넣어도 성능이 안올라간다. 10 CPU까진 쓸만하다.
3. Database

- NVME 디스크는 고성능 I/O가 필요한 경우에 사용한다
- 주의할 점은 클라우드 환경에서 NVME 디스크는 ephemeral한 구조이기 때문에 restart되면 데이터가 사라진다. 그래서 다중 가용영역을 활용하여 HA 구성이 필수이다.
- NVME는 클라우드 상품별로 성능 차이가 심한 편이다. 성능 지표는 IOPS를 기준. 최대 용량도 한계가 있다. 그래서 NVME를 사용하려면 고려할 것이 많다
- NVME는 보통 용량이 375GB 정도 밖에 안되기 때문에 여러개를 묶어서 사용해야 함 → RAID도 신경써야 함
예를 들어 I/O 분산을 위해 데이터를 여러 데이터에 분산 저장한다거나 그런 식으로 부하분산
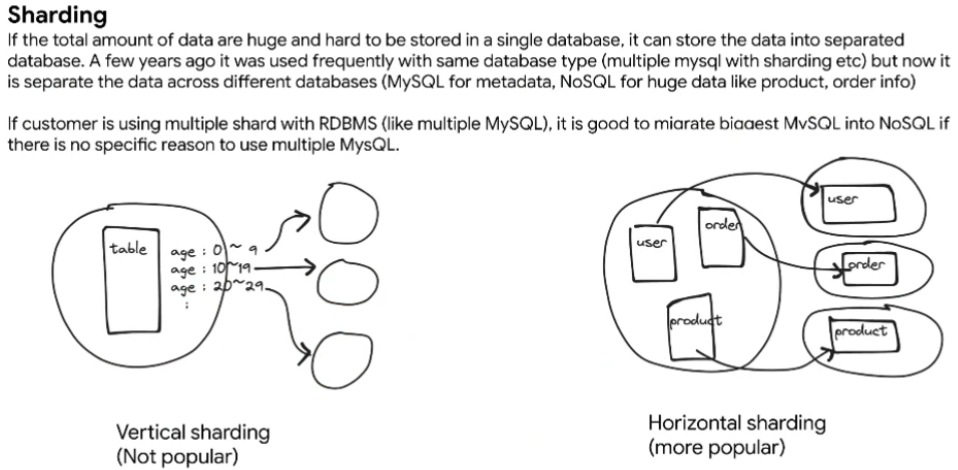
- 데이터 사이즈가 너무 커서 하나의 데이터베이스에 넣을 수 없을 때, 여러개의 데이터베이스로 분산해서 저장하는 구조를 샤딩 구조라고 부름
- Vertical Sharding은 데이터 I/O가 특정 한곳에 몰릴 수도 있고, JOIN를 쓰기도 쉽지 않기 때문에 잘 안 사용한다
- mysql를 여러개 쓰는 것뿐만 아니라 mysql+noSql 여러개 쓰는 것도 샤딩이라고 볼 수 있다
- 그래서 요즘은 샤딩이 거의 필수이고, Horizontal Sharding으로 간다 (상품 별로 나눔)
NoSQL

- KV Store는 put/get 만 되고 like던가 join은 기본적으로 안됨. Index를 사용하는 구조가 아니기 때문.
Secondary Index를 사용하는게 있긴 한데, 사실 이것도 Secondary Index로 Sorting이 되어있는게 아니기 때문에 랜덤으로 액세스를 하는 방식이다. 그래서 성능이 안나옴. 오히려 문제가 됨. 그래서 보통 Secondary Index는 잘 안씀. 정 Secondary Index가 필요한 경우가 있다면 역 정규화를 진행해서 똑같은 데이터인데 테이블을 두개를 만들어서 하나는 Primary Id가 유저 아이디, 다른건 Primary Id가 Age 이런식으로 Secondary Index로 사용하려고 했던 것을 또 하나의 Primary Id로 주어서 같은 테이블을 만들어서 사용 → 검색을 빠르게 하고, 데이터 액세스를 빠르게
cf) Document Store는 Json 구조라 Join 사용 가능 - JSON 들어가면 Document Store라고 생각하면 됨 ex) mongoDB

- No SQL의 속도가 RDBMS보다 압도적으로 빠른건 아니다
- 캐싱, 인덱스 때문에 데이터가 작은 경우에서는 RDBMS가 압도적으로 더 빠르다
- 그리고 NoSQL은 기본적으로 분산 DB이다. 그래서 기본적으로 네트워크 I/O를 동반한다
- 노드를 추가하기만 하면 데이터가 커져도 성능이 Linear하게 유지됨. 그래서 대용량 데이터를 사용할 때 NoSQL을 사용한다
- 일반적인 경우에는 MySQL만 사용해도 충분하다
- NoSQL은 join이 필요 없고 단순한 테이블일 때 사용하면 좋다. 예를 들어 모바일 이벤트 데이터, 유튜브의 비디오 목록 데이터라던지 이런 serial성 데이터 또는 키-값 형태는 NoSQL을 사용하는 것이 좋다. 데이터가 단순하고 스케일이 큰 경우에도 사용한다.
- RDBMS는 복잡하고 join이 필요하고 consistency를 강하게 요구하는 경우에 사용하는 것이 좋다. 웬만해서는 RDBMS로 충분하다. 특히 우리나라처럼 인구가 비교적 적은 경우에는 크게 문제 없음. 하지만 글로벌 서비스라면 스케일이 크다면 NoSQL 고려.
CAP Theorem
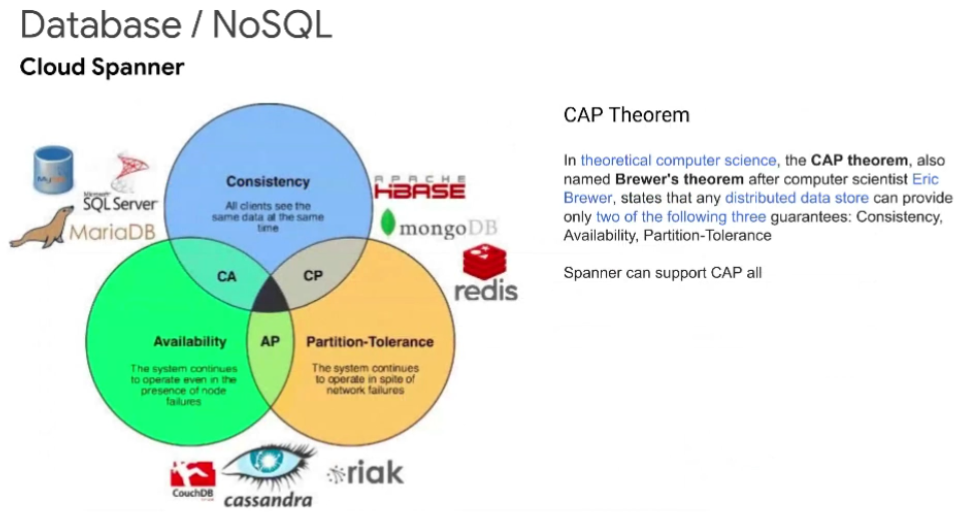
- CAP 정리는 다음과 같은 세 가지 조건을 모두 만족하는 분산 컴퓨터 시스템이 존재하지 않음을 증명한 정리이다.
- 일관성(一貫性, Consistency): 모든 노드가 같은 순간에 같은 데이터를 볼 수 있다
- 가용성(可用性, Availability): 모든 요청이 성공 또는 실패 결과를 반환할 수 있다
- 분할내성(分割耐性, Partition tolerance): 메시지 전달이 실패하거나 시스템 일부가 망가져도 시스템이 계속 동작할 수 있다
- 이 세가지를 다 만족하려면 원자 시계급으로 초정밀하게 트랜젝션의 순차가 틀어지지 않게 조정할 수 있는 정도는 되어야 함 ex) Google Spanner
비동기 호출 패턴

- api 서버로 request를 보내면 해당 호출에 대한 결과값을 바로 전달해주는게 아니라 응답코드만 보내주고 실제 동작은 큐에 들어가서 백그라운드에서 진행된다
- 이런 식으로 무언가를 요청하고 알아서 처리되겠지~하는걸 Fire & Forget 패턴이라고 부른다
Pub/Sub 패턴과 라우팅 패턴

- 하나의 메세지를 N개의 서비스에게 전달하고 싶을때 사용하는 패턴이다
- EventTrac이라는 오픈소스가 있는데 이걸 Router로 사용하는 패턴도 있다. 그래서 어떤 메세지는 어디로 가고 그런식으로 라우팅 기능도 추가할 수 있다
- 라우팅은 헤더에 라우팅키를 넣어서 어디로 라우팅할지 식별하면 됨 (body에 넣지 말자)
메세지 큐 고려할 점
1. 스케일링
- 큐 - 서버(subscriber) - DB 이런식의 구조가 있다고 가정해보자. 보통 subs들의 오토스케일링은 서버의 CPU 사용률을 기반으로 트리거를 걸어두게 되는데 위와 같은 구조에서는 서버가 DB에 트랜젝션을 보내놓고 기다리는 동안에는 사실상 CPU를 별로 사용하지 않는다. 그런데 DB에서 처리하는 시간이 길어서 오랫동안 기다리게 된다면? 큐에 계속 메세지가 쌓이게 됨. 오토스케일링을 걸어두었음에도 불구하고 큐가 오토스케일링이 되지 않게 되는 문제점이 발생하게 된다. 그래서 메세지 큐의 남아있는 길이를 지표로 삼아서 오토스케일링을 걸어야 한다. 이런걸 오픈소스로 만든 것이 Keda라는 것이 있다. 참고로 Keda는 쿠버네티스 위에서 동작한다. Keda는 많은 플랫폼의 서비스들과의 호환성이 매우 좋음.
- https://keda.sh/docs/2.13/
KEDA | The KEDA Documentation
Welcome to the documentation for KEDA, the Kubernetes Event-driven Autoscaler. Use the navigation to the left to learn more about how to use KEDA and its components. Additions and contributions to these docs are managed on the keda-docs GitHub repo.
keda.sh
- Spring이나 톰캣도 내부적으로는 Dispatcher Queue가 있고 CPU Utilization를 보고 Thread Pool를 오토스케일링하는 구조이다. JMX(Java Management eXtensions)를 사용하면 톰캣이나 Spring의 설정값을 가져오거나 모니터링할 수 있는데 이걸 이용해서 스케일링하면 더 좋은 구조로 만들 수 있다
- 하지만 불편한 진실... 기본적으로 오토스케일링은 제대로 작동을 안한다... 그래서 피크 타임을 예측해서 미리 걸어두던가 해야한다
- 오토스케일링은 애플리케이션 단에서 하는게 아니라 인프라 단에서 해야함. 예를 들어 AWS AutoScailing 또는 쿠버네티스 Horizontal Pod AutoScailing이 있다
2. 메세지 유실 방지
- 기본적으로 큐의 메세지는 메모리에 저장이 된다. 그래서 메세지가 계속 쌓이게 되어 메모리가 꽉 차면 메세지 큐가 죽어버린다. 그래서 필요한 것이 Scalable한 queue가 필요하다. 예시로 카프카가 있다. 하지만 트랜젝션을 보장해주지 않음.
- 메세지를 큐에다가 보내고 서버가 꺼내서 DB에 넣으려는데 넣기 전에 fail되면? 큐에는 메세지를 이미 꺼냈고, DB에 넣기 전에 fail되어서 데이터가 유실된다
- 트랜젝션을 보장해주는 경우에는 실패가 뜨면 롤백을 해서 메세지를 복구한다
- 하지만 카프카는 트랜젝션을 보장해주지 않음. 그래서 manual적으로 해주어야 함
try{ msg=getmsg(); } catch(Exception e){ ... } Ack();- 메세지 쓰다가 에러나면 catch문으로 처리
- 만약에 에러가 안났다고 하더라도 카프카는 일정 시간 동안 ack를 받지 못하면 메세지를 다시 롤백하기 때문에 밑에다가 ack() 처리를 해주면 된다 (만약에 트랜젝션을 보장해주는 서비스라면 ack 해줄 필요도 없음)
Fire & Forget VS Callback
- Fire & Forget은 요청을 보내고 알아서 하겠지~ 하는 것
- Callback은 요청을 보내고 바로 잘 전달했다고 응답을 받는 것 까지는 동일하지만, 처리가 끝나면 api로 응답을 보낸다
- 그렇기 때문에 Callback은 보낼 때 어떤 api가 보낸 것인지 식별할 수 있는 ID를 보내주어서 처리가 끝난 후 올바른 API에게 응답을 보낼 수 있도록 한다 (안 그러면 누가 보낸건지 알 수 없으므로)
비동기 패턴 정리
- 각각 Fire & Forget으로 할지 Callback으로 구성할지는 요구 사항에 따라 적용
1. MQ (메세지큐)

- 요청을 큐에 넣고 전달
2. Pub/Sub

- 하나의 메세지를 여러 target에게 전달
3. Routing
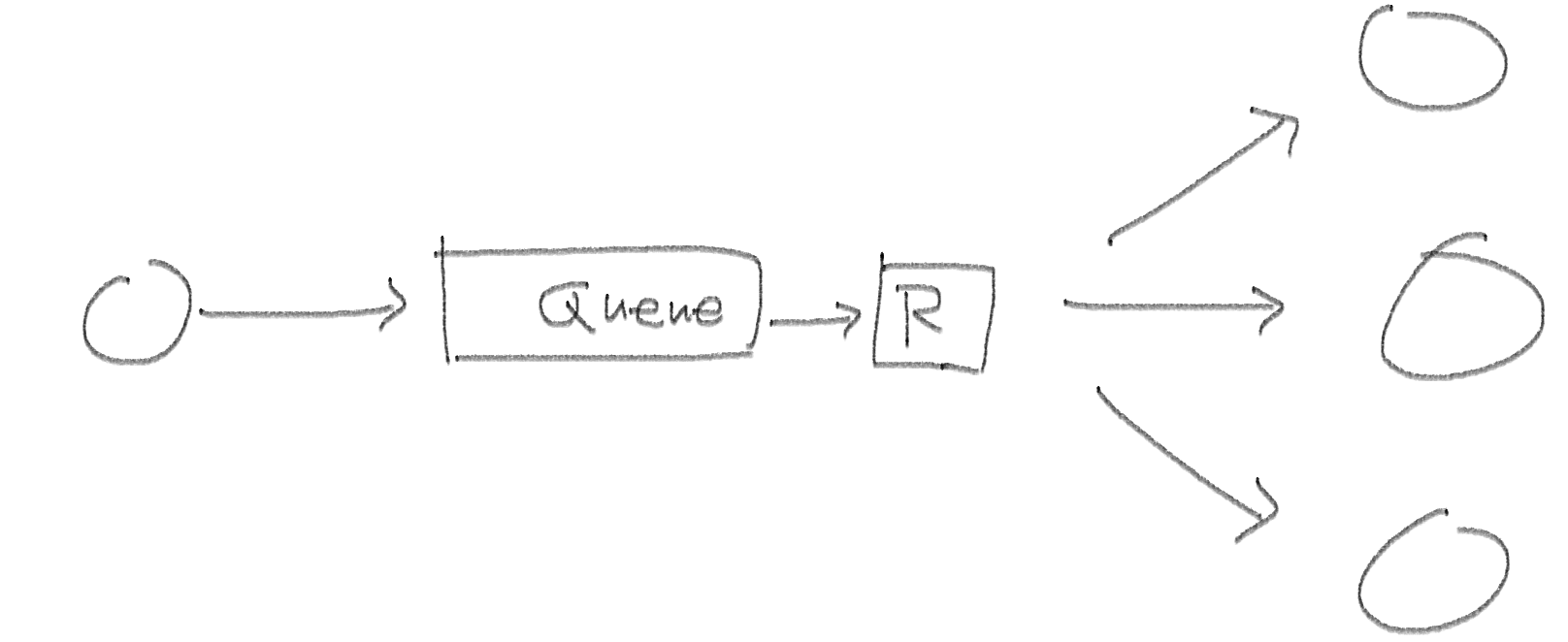
- 메세지를 특정 조건에 따라 라우팅
4. Error Hospital

- 에러가 나면 재시도를 하다가 N번 이상 에러가 나면 Error 큐로 메세지 전달
- Error 큐에서는 retry 또는 log 또는 human(manual) 처리
Matured Backend System Architecture

- 기업에서 빠른 NFS 서비스를 원할 경우 NetApp를 사용할 수 있다.
- https://www.netapp.com/cloud-services/
Cloud Services for IT and Data Management | NetApp
Get more out of the cloud with cloud services for IT and data management from NetApp®. Unlock the potential of the cloud while improving speed and efficiency.
www.netapp.com
- HPC를 요구하는 환경에서 예를 들어 유전자 분석과 같은 경우에 여러 서버가 하나의 데이터를 보고 사용해야 하기 때문에 이런 경우에 고성능의 NFS 서비스(NetApp은 굉장히 빠름)를 사용
반응형'아키텍쳐 > 레퍼런스 아키텍쳐 - Common' 카테고리의 다른 글
LLM 시스템 아키텍쳐 설계 (0) 2024.04.13 머신 러닝 시스템 아키텍쳐 설계 (0) 2024.04.08 빅데이터 시스템 아키텍쳐 설계 (데이터 매쉬) (0) 2024.04.07 백엔드 솔루션들 (2) 2024.03.24 이전글이 없습니다.댓글