- Overfitting 방지, CNN과 이미지의 상관 관계2024년 02월 29일 07시 44분 40초에 업로드 된 글입니다.작성자: 재형이반응형
- 강의를 들으면서 모르는 용어나 헷갈리는 용어가 나오면 구글링을 하고 있는데 게시된 날짜를 보면 막 2017년에 올라왔던 글이고 그렇다
- 근데 7년이 지난 지금 공부하는 입장으로서 뒤처지고 있는건 아닐까? 라는 막연한 두려움이 생긴다
- 그래도 해야지 머 ㅇㅉ은 맞긴한데
- 내가 어떻게 저 사람들을 따라잡고 뛰어넘을건지는 앞으로 계속 고민을 해봐야겠다
1. Overfitting 방지
- 트레이닝 때는 잘하는데 테스트 때는 잘 못하는 것이 오버피팅이다

- 너무 오버피팅이 되어 버리면 위 그림처럼 덜 오버피팅된 것이 미확인 데이터와 로스가 더 적어질 수도 있는 상황이 연출된다
1-1. 모델을 좀 더 단순하게
- 그럼 너무 깊은 인공 신경망을 써서 생기는 문제이니, 신경망을 단순하게 하면 되지 않냐!!
- 생각이 많으면 오히려 일을 그르치는 것처럼
혹시 저 부르셨나요? - 단순하게 모델을 경량화해보자라는 개념
1-2. Data Augmentation
- 트레이닝 시키는 데이터 양이 너무 적어서 발생하는 문제일 수도 있다
- 많지 않은 데이터에 대해서 오버피팅되어 버리면 우리가 원하는 미확인 데이터에 대해서 제대로 찾지 못해버린다
- 그래서 데이터를 여러가지 방법으로 증가시켜서 그걸로 트레이닝을 해보자 라는 개념

- 어차피 다 같은 강아지잖아~
- 그리고 데이터 하나로도 이렇게 많은 데이터셋을 만들 수 있다!
1-3. Validation data 기준, 가장 성능이 좋은 모델
- 테스트할 때 가장 로스값이 작은 곳을 찾고 싶지만 그건 힘드니
- Validation data 기준으로 테스트할 때 가장 로스값이 작았던 모델들을 저장해서 기억하고 있다가 그 모델을 쓰면 그나마 낫지 않을까?라는 개념

1-4. DropOut, DropConnect
1-4-1. DropOut
- Drop Out은 학습을 시킬 때 매번 모든 노드들을 고려할 필요가 있나? 실제로는 별 의미 없는 노드들이 있지 않을까? 란 식으로 매번 데이터가 들어갈 때마다 어떤 확률 p로 노드들을 제외하고 학습한다
- 레이어마다 어떤 확률 p(하이퍼 파라미터)를 정해주고 그 확률에 따라서 노드를 제외한다
- 이런 식으로 정해두면 해당 레이어에 있는 각각의 노드들은 70퍼 확률로 살고 30퍼 확률로 제외당한다


- 데이터마다 다른 네트워크를 통과하는 셈이다
- 그러고 테스트할 때는 다시 모든 노드들을 살린 상태로 테스트하는데 p값을 넣어서 학습했으므로 p값을 고려해서 나가는 W에 p 값을 곱해준다

Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." 67 The journal of machine learning research 15.1 (2014): 1929-1958 1-4-2. DropConnect
- Drop Connect는 학습을 시킬 때마다 노드를 제외하는 것이 아닌 엣지를 제외하는 것이다

- 드랍 아웃 이후 1년 정도 뒤에 나온 논문
1-5. Lp-Regularizaiton (p=1 or p=2)
- p가 2면 L2-Regularization , p가 1이면 L1-Regularization 이다
- p는 1 또는 2를 자주 사용하고 그 외의 것들을 사용하는 건 보지 못했다고 한다 (혁펜하임 피셜)
- Lp-Regularizaiton는 Loss에 Weight의 크기를 더해서 같이 고려하자라는 개념
- 즉, 단순히 L을 사용하는 것 대신 $L + \lambda \begin{Vmatrix} w \end{Vmatrix}^{p}_{p}$ 로 사용하는 것이다
- 람다는 하이퍼 파라미터이다
- 람다를 너무 크게 설정하면 로스를 별로 고려하지 않을 것이고, 그렇다고 너무 작으면 람다를 고려하지 않게 되므로 사용하는 의미가 사라짐 → 적절한 람다 크기를 정해야 함
- 처음에는 아무래도 L이 람다보다 더 클테니 L을 많이 고려하다가 L을 어느정도 줄었으면 L이 도로 커지지 않는 선에서 Lp를 줄이는 식인 것이다 → 순서가 항상 이렇다고 할 순 없음. 여튼 이런 개념

- 왜 이런 공식이 나왔는지는 증명을 안해주셔서 나도 모르겠음... 나중에 찾아봐야겠다
- 결국에 저렇게 L에 W를 더해준 것을 미분해서 사용하므로 L1-Regularization인 경우에는 W절댓값을 미분해서 사용하는 것이므로 항상 기울기는 일정할 것이고 그 말은 전체적으로 W 값을 조정해준다는 의미이다. 그래서 W가 가장 작은애가 먼저 사라질 가능성이 있음. 물론 그 W를 줄였을 때 L이 갑자기 커진다면 줄이지는 않겠지만.
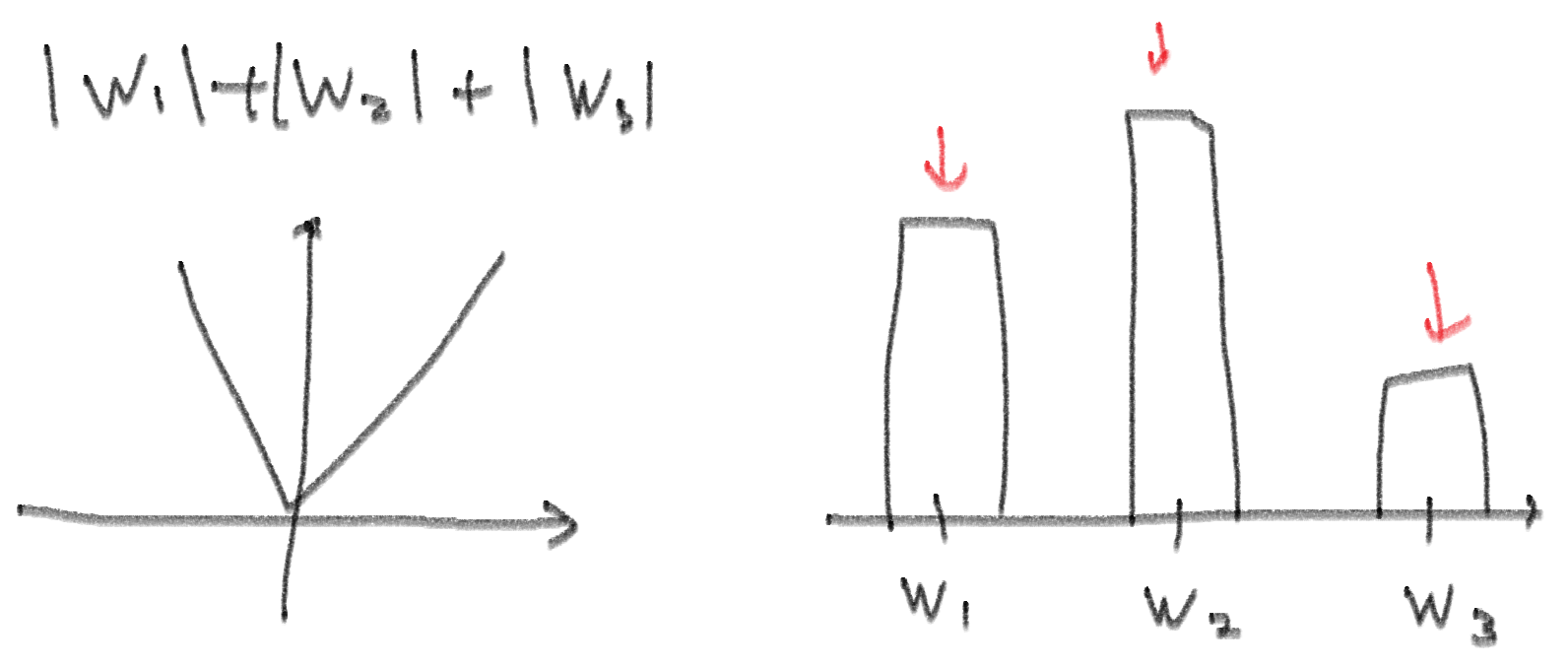
- L1-Regularization 같은 경우에는 미분(W1 편미분하면 나머지 W2랑 W3은 상수 취급)하면 이차함수 형태를 보일테니 기울기가 가장 큰 애를 위주로 더 줄여준다

- 가중치를 평준화 시켜서 골고루 고려할 수 있게 만들어줌
- 이렇게 각 노드들의 W를 조절함으로써 모든 필요한 애들만 고려할 수 있게 만들어주는 것이다
(W가 0이 되면 그 엣지는 드랍커넥션한거랑 같은 의미임, W는 곱해지니까) - 즉, 드랍커넥션처럼 랜덤으로 엣지를 죽이는 것이 아니라 로스를 계산할 때 가중치를 고려해서 좀 더 근거있게 엣지를 줄이는 것이다 → 근거있는 드랍커넥션
2. CNN과 이미지의 상관 관계
- 지금까지 MLP만 봤었다. 근데 CNN으로 이미지를 학습할 때 항상 모든 픽셀들을 학습시키게 하는 것이 맞을까?
- 그렇게 되면 일단 W의 갯수도 너~무 많아질테고 오버피팅이 되어 같은 강아지 사진이 주어졌을 때 배경이 달라졌다고 강아지로 인식하지 못하게 되는 경우가 발생할 것이다
- 인간의 사고 방식을 묘사하는 것이기 때문에 실제로 인간도 사진을 보고 판단할 때 모든 부분을 보는 것이 아니라 뇌의 일부분만 활성화된다는 연구 결과가 있다고 한다
- 이것처럼 모든 부분을 보는게 아니라 위치별 특징을 추출해서 학습시키는 것이다
- 눈, 코, 입의 위치가 어디있고 몸통은 어디있는지 이런 위치별 특징을 조합해서 강아지인지 고양이인지 판별할 수 있게 만드는 것이다
- 컨볼루션은 이런 위치별 패턴을 찾는 연산이기 때문에 컨볼루션을 신경망에 적용했다는 사실 자체만으로도 위치별 패턴이 존재한다라는 사전 정보를 모델에게 준 것과 같은 의미를 가지게 된다
2-1. Convolution
- 동일한 W셋 가지고 위치를 옮겨가면서 진행한다

- 그리고 이런 W 셋을 커널 혹은 필터라고 부른다. 물론 bias도 더해야 함. 근데 필터 값이 고정이므로 bias도 고정이다

- 예를 들어서 세로의 특징을 필터하는 W셋을 가지고 이미지를 쭉 스캔한다고 해보았을 때를 보면 다음처럼 나타난다

필터1: 세로 필터, 필터2: 가로 필터 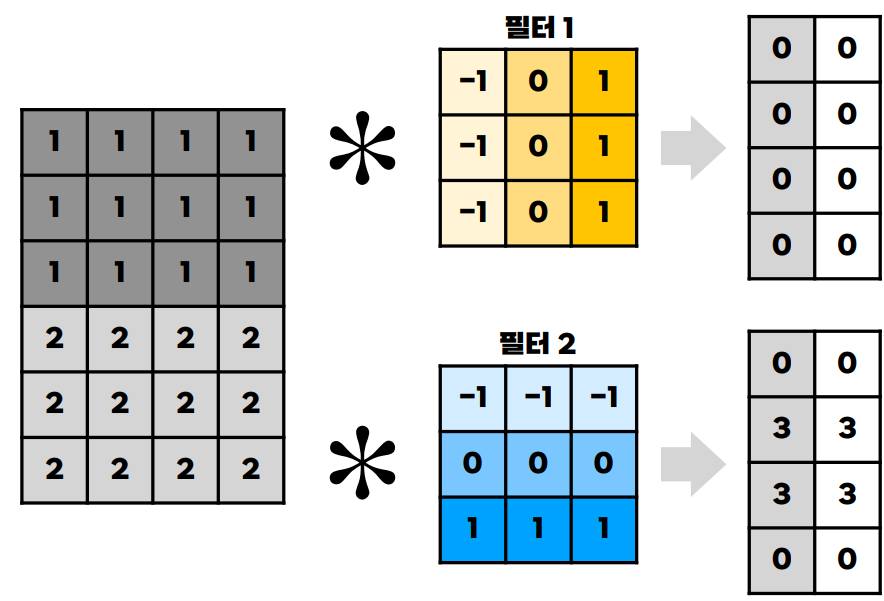
- 이런식으로 어느 위치에 얼만큼 특정 특징이 있는지 알 수 있다
- 실제 이미지에 적용해보면 세로 필터로 추출한 이미지는 세로 부분만 잘 살려졌고, 가로 필터로 추출한 이미지는 가로 부분만 디테일이 살려져 있는 것을 확인해볼 수 있다

- 이렇게 컨볼루션은 특징을 뽑을 수도 있고 응용하면 이미지에 변형을 가할 수도 있다

이미지에 블러 처리하기 - 이렇게 다양한 필터(가로 필터, 세로 필터 등)를 사용하여 특징별로 위치를 저장하자
- 각각의 컨볼루션 결과를 깊이 축(=채널 축)으로 쌓으면 여러가지 필터를 저장할 수 있다 (이런 걸 feature map이라고 부름)
- 커널 속의 W와 bias 값이 학습 파라미터이다

반응형'인공지능 > 인공지능 기초' 카테고리의 다른 글
RNN (0) 2024.03.02 컨볼루션, Padding, Stride, Pooling, CNN (0) 2024.03.01 Univeral Approximation Theorem, Vanishing Gradient 방지 (2) 2024.02.28 MSE, log-likelihood, MLE, 다중 분류 (2) 2024.02.27 비선형 액티베이션, 역전파, 이진분류 (6) 2024.02.26 이전글이 없습니다.댓글