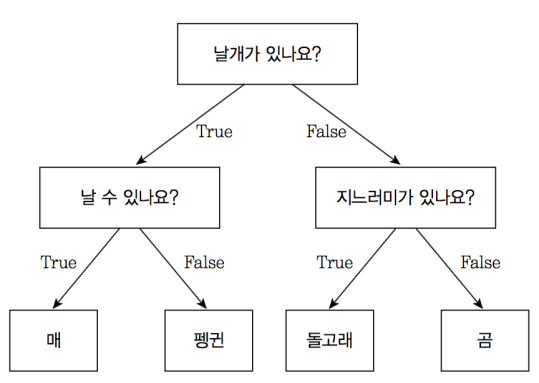
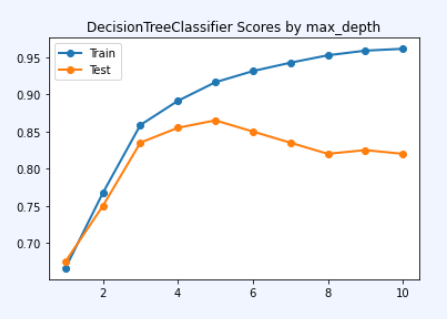
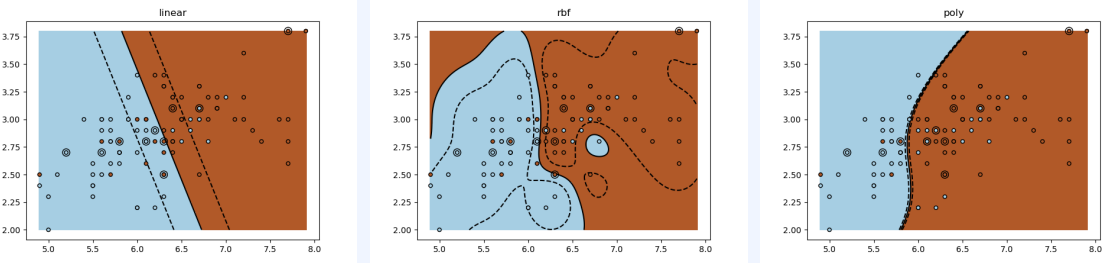
불균형한 데이터(한쪽에 치우친 데이터)의 경우 가중치를 조절하여 모델의 완성도를 높일 수 있음
sample_weight
class_weight
2. 분류 알고리즘 평가 방법
2-1. Confusion Matrix
Classification 모델이 가질 수 있는 결과를 Matrix로 나타낸 것
2-2. Accuracy
전체 예측에서 (예측이 Positive 이든 Negative 이든 무관하게) 정확하게 예측한 비율
2-3. Precision
Positive로 예측된 것들 중에서 실제로도 Positive인 비율
2-4. Recall or Sensitivity
실제로 Positive인 것들 중에서 예측이 Positive로 된 경우의 비율
2-5. F1 Score
Precision과 Recall의 조화평균
2-6. 지표 선택의 판단 근거 (어느 상황에 어떤 지표를 사용해야할까?)
데이터가 한쪽으로 치우친 상황이 아니면 Accuracy를 사용할 수 있다
하지만 데이터가 한쪽으로 치우친 상황이라면 Precision 또는 Recall를 사용해야 한다
그럼 Precision과 Reacll의 선택 기준은 무엇일까? → 주어진 상황에서 오판이 발생하면 크리티컬한 문제가 생길 경우를 판단 근거로 삼는다
예시1) A 의료원에서 환자가 암인지 아닌지 판단하는 모델을 개발했다. 이 모델의 성능 평가 지표로는 무엇을 사용하는게 좋을까?
암이 아닌데 암이라고 판단한 경우: 기분은 나쁠 수 있지만 실제로는 암이 아니므로 큰 문제는 발생 X
암인데 암이 아니라고 판단한 경우: 환자의 생명을 위협할 수 있을 정도로 매우 크리티컬한 상황이 발생할 수 있음
Reacll 사용
예시2) B 사이트는 이메일 서비스를 제공한다. 이메일이 스팸인지 아닌지 필터링하는 모델을 개발하였다. 이 모델의 성능 평가 지표는 무엇을 사용하는게 좋을까?
스팸인데 정상 메일이라고 판단한 경우: 사용자가 그냥 무시하거나 삭제해버리면 그만이다
정상 메일인데 스팸이라고 판단한 경우: 예를 들어 해외 인증 코드를 받아야 하는데 계속 인증코드 메일이 오질 않는다... 매우 화나는 경우가 발생한다.
하지만 Precision과 Recall을 너무 맹신해서는 안된다
값을 쉽게 조작할 수 있기 때문이다
Precision과 Recall을 서로 알맞게 사용하며 F1 Score 수치도 고려해주면서 평가를 진행해주어야 한다
3. 회귀 알고리즘
3-1. 선형회귀
선형회귀란 선형적인 데이터를 가지고, 미확인 데이터가 들어왔을 경우에 출력값을 예측하고 싶을 때 사용할 수 있다
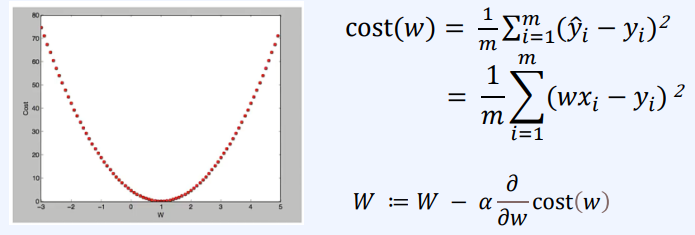
비용함수: 실제 정답과 예측한 값의 차이를 제곱하여 평균을 낸 것을 보통 사용, cost가 최소가 되도록 하는 W와 b를 구하는 것이 목표
비용함수의 최솟값이 되록하는 W와 b를 구하기 위해 경사하강법(그라디언트 하강법)을 사용할 수 있다
3-2. 다중 회귀 분석
과연 주어진 데이터를 모두 사용하는 것이 더 좋은 모델이라고 할 수 있을까? 아니다
학번, 키, 형제자매수가 성적에 영향을 준다고 보기에는 직관적으로 이해가 되지 않음
그리고 각 변수들이 서로 다중공선성을 가지고 있는 관계일 수도 있 수도 있기 때문에 여러 변수들을 넣어보기도 하고 빼기도 하면서 테스트를 진행해보아야 적절한 변수들을 찾아낼 수 있다 → 노가다ㅋ
선형 회귀 알고리즘에서 데이터 전처리 시에는 정답과 예측 값들의 오차를 가지고 가중치가 업데이트 되기 때문에 혼자서 오차가 엄청 큰 값이 있을 경우에 모델이 이상해질 수 있다(예를 들면 어떤 특징은 값들이 1~10까지 분포되어 있는데 어떤건 값들이 1~10000까지 분포되어 있음). 그래서 데이터 전처리 시에 전체적인 feature에 대한 스케일을 맞춰주는 작업이 필요하다. 그리고 선형 회귀 알고리즘은 데이터들이 정규분포 형태를 가진다고 가정하고 진행하기 때문에 어떤 feature가 한쪽을 쏠려있는 형태를 가진다고 로그 스케일로 변환을 주어서 정규분포 형태를 가질 수 있도록 해주어야 한다
3-3. 로지스틱 회귀 분석
종속 변수가 이항형 문제일 때 사용
단순 선형 회귀 알고리즘으로는 정확하게 판단하기 어렵기 때문에 시그모이드 함수를 사용한다
4. 회귀 알고리즘 평가 방법
데이터($y$)의 분포의 평균: $\bar{y}$
데이터($y$)의 분포의 평균: $\hat{y}$ (예측값)
4-1. 회귀 알고리즘 평가 지표
SSE(Sum of Squares Explained)
변동 값
데이터($y$)와 예측값($\hat{y}$)의 차이의 제곱의 합
SSR(Sum of Squares Regression)
회귀 모델로 설명이 되는 분산(평균으로 부터 얼마나 떨어져있는가)
실제값의 평균($\bar{y}$)과 예측값($\hat{y}$)의 차이의 제곱의 합
SST(Sum of Squares Total)
실제 데이터의 전체 분산
SST=SSR+SSE
4-2. 회귀 알고리즘 평가 방법
R-Square(R2)
회귀 분석 모형의 설명력을 나타내는 척도로, 항상 평균을 출력하는 예측모델보다 성능이 얼마나 더 좋은가를 나타내는 지표
예) R2=0.7 인 경우, 종속변수, 독립변수의 변화가 회귀분석 모형으로 70% 정도 설명된다고 해석 가능
1에 가까울수록 성능이 좋고, 0에 가까울수록 성능이 떨어짐
수정된 결정계수 (Adjusted R-Square)
결정계수의 문제점: 독립변수의 갯수가 많아질수록 결정계수의 값이 무조건 증가함
회귀모형에 적합하지 않은 변수를 투입 시, 이에 대한 패널티 부여
테스트용 데이터를 활용하여 모델의 성능을 평가
예측값과 실제 정답을 비교하여 평가
MSE, MAE, MAPE 사용
회귀 모델을 평가함에 있어서 단순히 평가 지표의 크기만을 가지고는 판단하기 어렵다. 여러가지 회귀 모델의 평가 지표 값의 크기를 비교해가며 가장 좋은 형태를 보여주는 모델을 선택하는 것이 바람직하다