- 리눅스 운영의 기초 : 시스템 및 프로세스 관리2024년 01월 21일 20시 45분 17초에 업로드 된 글입니다.작성자: 재형이반응형
- 운영을 잘하기 위해서는 운영체제의 기본 정도는 알고 있어야 할 것 같다는 생각이 들어서 리눅스를 공부하게 되었다
- 너무 딥하게 들어가지는 않을 것이고 기초 위주로 정리를 해볼 생각이다. 왜냐하면 초반부터 딥하게 들어가려고 하면 지칠 것 같기 때문이다ㅎ;;
- 어차피 오늘만 할 것도 아니고 꾸준하게 오랫동안 공부할 것이기 때문에 차근차근 쌓아올릴 것이다

리눅스 운영의 기초 포스팅
리눅스 운영의 기초 : 시스템 및 프로세스 관리
운영을 잘하기 위해서는 운영체제의 기본 정도는 알고 있어야 할 것 같다는 생각이 들어서 리눅스를 공부하게 되었다 너무 딥하게 들어가지는 않을 것이고 기초 위주로 정리를 해볼 생각이다.
jaehyeong.tistory.com
리눅스 운영의 기초 : 파일시스템, 소프트웨어 및 사용자 관리
지난번에 이어서 리눅스 기초 정리 1. 파일 시스템 (파일 시스템 이해, 마운트, 디렉토리 구조 등) 1-1. 파일 시스템 스토리지 장치에 파일을 명명하고, 저장하고, 읽어내는 방법을 제공하는 시스
jaehyeong.tistory.com
리눅스 운영의 기초 : 스크립트 및 설정 자동화
리눅스 쉘 스크립트 및 IaC 도구 중 하나인 Ansible 기초 정리 리눅스 운영의 기초 포스팅 😎 리눅스 운영의 기초 : 시스템 및 프로세스 관리 리눅스 운영의 기초 : 시스템 및 프로세스 관리 운영을
jaehyeong.tistory.com
1. 부팅 및 시스템 관리 데몬의 이해 (부팅 프로세스, systemd 등)
1-1. 리눅스 부팅 순서
- 리눅스 부팅은 크게 다음과 같이 볼 수 있다
- 펌웨어 (BIOS 또는 UEFI 로드)
- 전원을 공급하는 순간 메인보드는 리셋 백터(Reset Vector : CPU가 리셋 후 실행할 첫 번째 명령어가 있을 것이라고 예상하는 메모리 위치)를 통해 CPU가 BIOS 코드를 호출
- 하드웨어 검사
- 파티션 식별 후 부트로더 실행
- 저장 공간의 첫번째 데이터 공간(0번 섹터,512byte)에서 MBR을 실행
- 부트로더(GRUB)가 커널을 로드
- /boot/grub 파일에 시스템에 직접 접근하여 커널을 메모리에 로드
- 커널 실행
- 커널은 컴퓨터의 각종 하드웨어를 사용하는데 필요한 드라이버와 모듈을 로드
- 주변 장치 확인 후 /var/log/dmesg 파일에 기록
- swapper 프로세스(PID0)를 호출 - 프로세스 스케줄링을 담당하는 스케줄러 역할
- Root File System("/")을 마운트
- Init 프로세스(PID1)를 호출
- Init/systemd 시작
- 시작 스크립트 실행
- 시스템 실행

1-2. BIOS vs UEFI / MBR vs GPT
- 펌웨어(BIOS,UEFI)는 컴퓨터에 전원이 공급되면 실행되는 최초의 프로그램이다
- 펌웨어(BIOS,UEFI)는 메인보드에 연결된 디바이스를 초기화하고 검사(POST,power on self test)하는 역할을 수행한다
- 부트로더를 메모리로 읽어오는 기능을 수행한다
📢 펌웨어(BIOS,UEFI) 시스템 정보 읽는 방법
# dmidecode ## - DMI 테이블 정보를 사람이 읽을 수 있는 형태로 출력해주는 도구 ## - DMI 테이블 : 하드웨어 구성 요소에 대한 정보를 추적하기 위한 산업 표준 ## -> 시스템 하드웨어 정보, 시리얼 번호, BIOS 리비전 등의 정보가 유지됨 // 사용법 dmidecode -t memory
- 참고로 AWS EC2 같은 경우에는 가상 환경이기 때문에 dmidecode -t memory를 실행하면 대부분의 값들이 Not Specified로 출력이 된다

PC 펌웨어
BIOS (Basic Input/Output System) UEFI (Unified Extensible Firmware Interface) 전통적인 펌웨어로 레거시 바이오스라고도 부름 바이오스를 계승해서 좀 더 정형화하고 더 표준적인 PC 펌웨어 부팅시 BIOS는 MBR이라는 특정섹터를 이용하지만, UEFI는 GPT 파티션으로 특정섹터를 지정하지 않음 복수의 운영체제의 선택이 가능함
(예, 윈도우7, 윈도우10, 리눅스, 맥OS 중에서 선택가능)PC 환경에서는 UEFI가 표준이 되어가고 있지만, 가상화 환경에서는 레거시 BIOS가 여전히 많이 사용되고 있음
- Intel 및 AMD 인스턴스 유형 → 레거시 BIOS에서 실행
- Graviton 인스턴스 유형 → UEFI에서 실행2TB 이상 스토리지를 지원(GPT 지원), 더 빠른 부팅 시간, GUI 환경(마우스 드라이버 지원) 디스크 파티션 기술 (단순한 물리 저장장치를 논리적으로 나누는 기술)
- 파티션은 역할에 따라 시스템 파티션, 부트 파티션으로 호칭
- 부트 파티션은 부트 로더가 저장되어 있는 영역으로 주 파티션
- 시스템 파티션은 운영체제가 담긴 파티션
- 이 두 개의 파티션은 같을 수도, 다를 수도 있다. 리눅스를 예를 들면 부트 파티션과 시스템 파티션은 동일하다. 그리고 부트로더 데이터를 /boot에 저장한다.
- MBR은 디스크의 첫 번째 섹터 (Sector 0)를 의미한다. 이 영역에는 파티션를 구성하고 있는 정보와 부트로더를 실행하기 위한 가장 기본적이고 첫 번째로 실행되어야 할 코드가 담겨있다. 그리고 GPT(GUID Patition Table)도 MBR 영역 개념을 활용하고 있다.
- 펌웨어는 MBR이든 GPT이든 MBR 영역을 첫 번째로 실행하고 이 코드가 어딘가 저장되어 있는 부트로더를 이어서 실행하고 마지막으로 운영체제를 읽어와 실행하게 된다. 이것이 펌웨어부터 이어지는 부팅과정이다.
- MBR과 GPT의 차이는 부트로더의 위치 차이이다. MBR은 기술 규약에 따라 부트로더가 MBR 영역에 이어서 저장되어 한다. 하지만 GPT는 부트로더의 위치를 따로 정하지 않는다.
MBR (Master Boot Record) GPT (GUID Patition Table) 디스크 공간의 2테라바이트까지만 가능 (32bit 체제이기 때문) 디스크 공간의 2테라바이트 이상 가능 (64bit 체제이기 때문), 그렇기 때문에 하드 드라이브의 용량이 크다면 (3TB 이상) MBR보다는 GPT를 이용해서 포맷해야 함 MBR (마스터 부팅 기록)의 메인 파티션의 최대 숫자는 네개까지입니다. 4개 이상의 파티션을 원하신다면, 기본 파티션 세개와 확장 파티션을 하나 생성해서 논리 파티션으로 나누어야 함 논리 파티션의 숫자의 제한을 없애고 128개의 주요 파티션까지 생성할 수 있음 특정 파티션이 손상됐을 때 다른 파티션을 사용할 수도 있습니다 (백업 기능) 데이터와 시스템을 많은 파티션으로 나누는 GPT와 달리, MBR은 부팅 데이터와 파티션을 결합시킵니다. 시스템 손상이 발생했을때, 결함이 있는 MBR OS 디스크에서 데이터를 복구하는 것은 위험합니다. GPT 드라이브는 에러 복구 코드 (ECC)을 도입해서 데이터 보안을 향상시킬 수 있습니다 BIOS 펌웨어는 GPT를 지원하지 못하기 때문에 이를 사용하기 위해서는 반드시 UEFI 펌웨어를 사용해야 함 1-3. 부트 로더
- 사용 가능한 커널을 확인하고 로드하는 작업을 수행
- 대부분의 부트 로더는 부팅 타임에 사용 가능한 운영체제를 선택하기 위한 UI를 제공
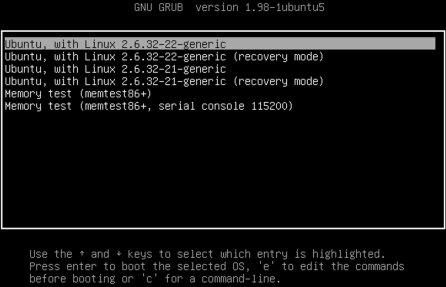
- 부트 로더 종류
- GRUB (GNU Grand Unified Boot Loader)
- 리눅스 시스템에서 널리 사용되는 부트 로더로, 다양한 운영 체제와 호환됩니다.
- LILO (Linux Loader)
- 오래된 리눅스 부트 로더로, GRUB에 비해 기능이 제한적이지만 여전히 일부 시스템에서 사용됩니다.
- GRUB (GNU Grand Unified Boot Loader)
- GRUB 설정
- /boot/grub/grub.cfg 파일 수정
- 부팅 옵션: debug, init=/bin/bash, root=/dev/foo, single
- init=/bin/bash 옵션을 사용할 때,
- 파일 시스템은 대개 읽기 전용(Read-Only)으로 마운트됩니다. 쓰기를 위해서는 수동으로 파일 시스템을 읽기/쓰기 모드로 재마운트해야 합니다(mount -o remount,rw /)
- init 프로세스(시스템의 첫 번째 프로세스로 일반적으로 PID 1을 갖는)를 시작하지 않고 대신 /bin/bash 셸을 초기 프로세스로 실행합니다. 이 경우, Bash 셸이 PID 1을 가지게 됩니다.
- 표준 부팅 과정에서 init 또는 그에 상응하는 시스템의 첫 번째 프로세스(예: systemd)는 시스템 부팅 시 다른 모든 필수 서비스와 프로세스를 시작하는 역할을 합니다. 그러나 init=/bin/bash 옵션을 사용하면 이러한 표준 부팅 과정이 생략되고, 시스템은 최소한의 환경에서 실행됩니다.
- 시스템은 단일 사용자 모드로 실행됩니다.
- 대부분의 서비스나 백그라운드 프로세스는 시작되지 않습니다.
- 네트워크 서비스, 로깅 시스템 등도 기본적으로는 활성화되지 않습니다.
- 파일 시스템은 일반적으로 읽기 전용으로 마운트됩니다.
- init=/bin/bash 옵션을 사용할 때,
- GRUB은 일반 텍스트 파일로 설정을 관리하는데 운영체제가 구동전임에도 불구하고 대부분의 파일시스템을 인식할 수 있기 때문에 가능한 것이다 (ext3, ext4, BtrFS, ZFS, FAT32, exFAT)
- 그래서 이런 것도 할 수 있다
- 배경 이미지 교체 (grub.cfg)
GRUB_BACKGROUND=“파일경로”
- 배경 이미지 교체 (grub.cfg)

GRUB 배경 이미지 변경 - AWS에서 커널 업데이트로 인해 기존에 사용하던 Amazon EC2가 부팅 오류가 생길 경우 해결방법
https://repost.aws/ko/knowledge-center/revert-stable-kernel-ec2-reboot
업데이트로 인해 Amazon EC2 인스턴스를 재부팅하지 못하는 경우 안정적인 커널로 되돌리기
업데이트로 인해 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 재부팅하지 못하는 경우 안정적인 커널로 되돌리려면 어떻게 해야 합니까?
repost.aws
1-4. INIT 시스템 - 시작 서비스 - PID 1
- init 시스템은 SysV 및 Systemd로 구분된다
- SysV init
- 시스템 구동 시 최초로 실행되는 사용자 레벨 프로세스
- 시스템 구동에 필요한 각종 스크립트를 실행한다
- /etc/init.d/rc 명령 실행 (ex. Debian : /etc/init.d/rc.S)
- 컴퓨터 이름 설정
- 타임존 설정
- 파일 시스템 마운트
- 네트워크 인터페이스 구성, 네트워크 서비스 시작
- /tmp 오래된 파일 삭제
- 기타 데몬 시작
- /etc/init.d 및 /etc/rcN.d
- /etc/init.d 의 실행 가능한 서비스들 모두 실행(cron, ssh, lpd 등등)

- 지정된 런레벨에 해당하는 스크립트 및 서비스 실행
- 런레벨이 5일 경우 → /etc/rc5.d/ 디렉토리 내부에 있는 스크립트 실행

- 실행 레벨
- single user : 파일시스템 마운트, 네트워크 비활성화, 시스템 관리용 쉘 접근
- multi-user : 일반적인 사용자 접근

- Systemd init
- Systemd는 현대적이고 빠른 부팅 시간을 목표로 하는 초기화 시스템 및 시스템 관리자 도구입니다.
- 서비스는 "unit" 파일로 관리되며, /etc/systemd/system/에 위치합니다.
- 병렬 처리를 통해 더 빠른 부팅 시간을 달성합니다.
- Systemd는 실행 레벨 대신 "target"을 사용하여 부팅 프로세스를 관리합니다.
1-5. Systemd 좀 더 파헤치기
- Systemd 주요 역할
- 병렬 실행 : 서비스를 병렬로 시작하여 부팅 시간을 최적화합니다.
- 종속성 모델 관리 : 서비스가 다른 서비스에 의존할 때, systemd는 의존성을 해결하여 서비스가 올바른 순서로 시작되고 종료되도록 합니다.
- 커널 로그 엔트리 관리 (journald)
- 네트워크 연결 관리(networkd)
- 로그인 관리 (logind)
- Systemd Unit
- Systemd가 관리하는 기본 개체 단위
- Systemd 관리용 도구 : systemctl
ex) systemctl list-units -t service : 실행 중인 서비스 목록 확인 cf. systemctl list-units-files -t service : 실행 여부와 상관 없이 모든 설치된 서비스 확인 - Unit 파일은 ini 파일 형식
- Systemd Unit 유형
- Service Units (*.service) : 가장 일반적인 유닛 유형으로, 시스템 서비스를 관리합니다. 서비스는 백그라운드에서 실행되는 프로세스를 말하며, systemd를 통해 시작, 중지, 재시작 및 상태 관리가 가능합니다.
- Socket Units (*.socket) : 소켓 기반의 통신을 위한 유닛입니다. 소켓 유닛을 사용하면 서비스를 요청에 의해 지연시켜 활성화시킬 수 있습니다. 이는 네트워크 소켓이나 IPC 소켓을 관리하는 데 사용됩니다.
- Device Units (*.device) : 시스템의 물리적 장치를 나타냅니다. udev에 의해 자동으로 생성되며, 특정 장치와 연관된 서비스를 시작하는 데 사용될 수 있습니다.
- Mount Units (*.mount) : 파일 시스템 마운트 포인트를 관리합니다. /etc/fstab에 정의된 마운트 포인트가 systemd에 의해 자동으로 .mount 유닛으로 변환됩니다.
- Automount Units (*.automount) : 자동 마운트 기능을 제공합니다. 이 유닛은 특정 경로에 접근이 발생할 때 파일 시스템을 자동으로 마운트하도록 설정할 수 있습니다.
- Target Units (*.target) : 관련된 유닛 그룹을 묶는 데 사용됩니다. 목표(Target) 유닛은 시스템 부팅 과정에서 특정 단계를 표시하거나, 서비스들의 그룹을 관리하는 데 사용됩니다. 예를 들어, multi-user.target, graphical.target 등이 있습니다.
- Timer Units (*.timer) : cron과 유사한 기능을 수행하여 특정 시간에 서비스를 시작하거나 반복적인 작업을 스케줄링하는 데 사용됩니다.
- Path Units (*.path) : 파일 시스템의 특정 경로를 감시하고, 변경이 감지되면 연관된 유닛을 활성화합니다.
- Slice Unit (*.slice) : cgroups를 통한 리소스 관리를 위해 사용되며, 시스템의 프로세스를 그룹화하여 리소스 할당을 관리합니다.
- Scope Units (*.scope) : systemd에 의해 동적으로 생성되며, 주로 시스템 외부에서 생성된 프로세스(예: 사용자의 쉘 스크립트)를 관리하는 데 사용됩니다.
- Systemd 유닛 주요 섹션 별 설명

- [Unit] 섹션 : 유닛의 일반적인 정보와 의존성을 정의합니다. 명시적으로 요청되지 않은 경우 직렬적인 종속성은 없음 → 병렬적 수행이 용이하도록 설계됨
- Description: 유닛에 대한 간단한 설명을 제공합니다, 사람이 읽을 수 있는 Unit정보. 레이블로 활용
- Requires, Wants: 다른 유닛에 대한 의존성을 정의합니다. Requires는 강한 의존성(종속성을 가진 unit이 실패하는 경우 서비스가 종료됨), Wants는 약한 의존성을 나타냅니다.
- After, Before: 다른 유닛에 대한 순서 의존성을 정의합니다.
- Conflicts: 충돌하는 다른 유닛을 지정합니다.
- [Service] 섹션 : 서비스 유닛(.service)에 특화된 옵션을 정의합니다.
- Type: 서비스의 시작 방식을 정의합니다. 예: simple, forking, oneshot, notify, dbus 등.
- ExecStart: 서비스를 시작할 때 실행할 명령어를 지정합니다.
- ExecStop: 서비스를 중지할 때 실행할 명령어를 지정합니다.
- Restart: 서비스 재시작 정책을 설정합니다. 예: always, on-failure, never 등.
- [Install] 섹션 : systemctl enable 명령어를 사용하여 유닛을 활성화할 때의 동작을 정의합니다.
- WantedBy, RequiredBy: 해당 유닛이 활성화될 때 연결될 대상(Target)을 지정합니다, Unit간 종속성 지정 (예, multi-user.target : 해당실행모드 구동 시 자동실행)
- Alias: Unit을 등록할 때 사용하는 이름 (예, systemctl enable sshd.service)
- [Socket] 섹션 : 소켓 유닛(.socket)에 특화된 옵션을 정의합니다.
- ListenStream, ListenDatagram, ListenSequentialPacket: 소켓이 수신 대기할 주소와 포트를 지정합니다.
Accept: 각 연결에 대해 별도의 인스턴스를 생성할지 여부를 결정합니다.
- ListenStream, ListenDatagram, ListenSequentialPacket: 소켓이 수신 대기할 주소와 포트를 지정합니다.
- [Mount] 섹션 : 마운트 유닛(.mount)에 대한 옵션을 정의합니다.
- Where: 마운트 포인트의 경로를 지정합니다.
- What: 마운트할 장치나 파일 시스템을 지정합니다.
- Type, Options: 파일 시스템 타입과 마운트 옵션을 지정합니다.
- [Automount] 섹션 : 자동 마운트 유닛(.automount)에 특화된 옵션을 정의합니다.
- Where: 자동 마운트 포인트의 경로를 지정합니다.
- TimeoutIdleSec: 비활성 상태 후 마운트 해제까지 대기하는 시간을 설정합니다.
- [Timer] 섹션 : 타이머 유닛(.timer)에 특화된 옵션을 정의합니다.
- OnCalendar, OnActiveSec, OnBootSec, OnUnitActiveSec: 타이머가 활성화되는 시간을 지정합니다.
- Persistent: 타이머가 놓친 작업을 추후에 실행할지 여부를 설정합니다.
- [Path] 섹션 : 경로 유닛(.path)에 특화된 옵션을 정의합니다.
- PathExists, PathExistsGlob, PathChanged, PathModified: 파일 또는 디렉토리의 특정 상태 변경을 감지합니다.
- [Unit] 섹션 : 유닛의 일반적인 정보와 의존성을 정의합니다. 명시적으로 요청되지 않은 경우 직렬적인 종속성은 없음 → 병렬적 수행이 용이하도록 설계됨
2. 프로세스 관리 (프로세스 구성요소, 라이프 사이클 등)
2-1. 프로세스 vs 쓰레드
- 프로세스란?
- 개발자들이 만들어 놓은 코드 덩어리를 메모리에 올려놓고 운영체제로부터 CPU 자원을 할당받아 프로그램이 실행되고 있는 상태
- 쓰레드란?
- 실행되고 있는 하나의 프로세스 내에서 동시에 여러 행동을 할 수 있게 해주는 작은 작업 단위
- 이전에는 프로세스를 실행하면 해당 프로세스가 끝날 때까지 기다렸지만, 쓰레드의 등장 덕분에 동시에 여러 작업을 할 수 있게 되었다
👩💻 완전히 정복하는 프로세스 vs 스레드 개념
한눈에 이해하는 프로세스 & 스레드 개념 전공 지식 없이 컴퓨터의 프로그램을 이용하는데는 문제 없어 왔지만 소프트웨어를 개발하는 사람으로서 컴퓨터 실행 내부 요소를 따져보게 될때, 아
inpa.tistory.com
2-2. 프로세스 디스크립터
- 프로그램 진행 상태를 완전하게 나타내는 자료구조의 집합
(실행중인 프로그램 코드 PID, 열린 파일, 지연된 시그널 리소스, 내부 커널 데이터, 프로세서 상태, 주소 공간 등) - 리눅스에서는 task_struct 구조체로 관리하고 있다. 이 구조체는 프로세스에 대한 거의 모든 정보를 포함하며, 프로세스의 생성, 관리, 스케줄링, 종료 등에 중요한 역할을 합니다.
2-3. 프로세스 라이프 사이클
- 신규 프로세스 생성 시 일어나는 과정

- fork 시스템 콜로 프로세스 복제
- 프로세스 복제: fork 시스템 콜은 호출한 프로세스(부모 프로세스)를 복제하여 새로운 프로세스(자식 프로세스)를 생성합니다.
- 반환 값:
- 자식 프로세스: fork는 자식 프로세스에게 0을 반환합니다.
- 부모 프로세스: 부모 프로세스에게는 새로 생성된 자식 프로세스의 PID(프로세스 식별자)를 반환합니다.
- exec 계열 함수 호출
- 프로그램 교체: 자식 프로세스는 exec 계열의 함수(예: execl, execv 등)를 호출하여 현재 실행 중인 프로그램을 다른 프로그램으로 교체합니다.
- exec 호출 후, 새 프로그램의 코드가 현재 프로세스에서 실행되기 시작합니다. 이때 자식 프로세스의 메모리 이미지가 새 프로그램의 이미지로 대체됩니다.
- 자식 프로세스 종료와 wait 호출
- 자식 프로세스 종료: 자식 프로세스가 작업을 완료하고 종료되면, 운영 체제는 해당 프로세스의 상태 정보를 유지합니다. 이 상태 정보는 부모 프로세스가 결과를 확인할 수 있게 해줍니다.
- wait 시스템 콜: 부모 프로세스는 wait 계열의 시스템 콜을 사용하여 자식 프로세스의 종료를 기다리고, 종료 상태를 회수합니다. 이를 통해 "좀비 프로세스"가 되는 것을 방지합니다.
- 부모 프로세스가 먼저 종료되는 경우
- 고아 프로세스: 부모 프로세스가 자식 프로세스보다 먼저 종료되면, 자식 프로세스는 "고아 프로세스"가 됩니다.
- init 프로세스의 역할: 리눅스 시스템에서는 이러한 고아 프로세스를 init 프로세스(현대 시스템에서는 systemd)가 자동으로 인수합니다. init 프로세스는 고아 프로세스의 종료를 기다리고 상태 정보를 회수하여, 자원 누출을 방지합니다.
- fork 시스템 콜로 프로세스 복제
2-4. 프로세스 상태
- 프로세스 상태는 프로세스의 현재 동작을 나타내며, 시스템의 리소스 관리 및 스케줄링에 중요한 역할을 합니다. 각 상태는 프로세스의 실행 가능 여부, 대기 상태, 종료 상태 등을 나타냅니다.

- TASK_RUNNING
- 설명: 프로세스가 CPU에서 실행 가능한 상태입니다. 실제로 실행 중이거나 실행을 위해 대기(runqueue) 상태에 있습니다.
- 특징:
- 실행 큐에 있으면 언제든지 CPU에서 실행될 수 있습니다.
- CPU 자원을 활발히 사용하는 상태입니다.
- TASK_INTERRUPTIBLE
- 설명: 프로세스가 특정 조건이나 이벤트를 기다리며 대기(sleep) 상태에 있습니다.
- 특징:
- 기다리는 이벤트가 발생하거나 시그널을 받으면, TASK_RUNNING 상태로 전환됩니다.
- 이 상태는 I/O 요청이 완료되기를 기다리거나, 사용자 입력을 기다리는 등의 상황에서 발생합니다.
- 시그널 대응: 이 상태의 프로세스는 시그널을 받을 수 있으며, 적절한 시그널 처리 후 TASK_RUNNING 상태로 돌아갈 수 있습니다.
- TASK_UNINTERRUPTIBLE
- 설명: TASK_INTERRUPTIBLE과 유사하지만, 시그널에 의해 깨어나지 않는 대기 상태입니다.
- 특징:
- 일반적으로 디스크 I/O와 같이 중단되면 안 되는 작업을 수행할 때 사용됩니다.
- 이 상태의 프로세스는 시그널을 받더라도 반응하지 않으며, 기다리고 있는 조건이 충족되어야만 TASK_RUNNING 상태로 돌아갑니다.
- 사용 예: Semaphore 세마포어(공유된 자원에 여러 개의 프로세스가 동시에 접근하면서 문제가 발생하는 것을 방지하기 위한 기술, cf. Mutex 뮤텍스)를 획득하고 중요한 작업을 수행 중인 경우 등
- TASK_ZOMBIE
- 설명: 프로세스가 종료되었지만, 부모 프로세스에 의해 그 상태가 회수되지 않은 상태입니다.
- 특징:
- 프로세스의 메모리는 해제되었지만, 프로세스 디스크립터(task_struct)와 종료 상태는 여전히 유지됩니다.
- 부모 프로세스가 wait 시스템 콜을 통해 종료 상태를 회수할 때까지 유지됩니다.
- TASK_STOPPED
- 설명: 프로세스가 외부에서 일시 중지된 상태입니다. 보통 디버거와 같은 외부 프로세스에 의해 중지됩니다.
- 특징:
- SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU 등의 시그널에 의해 발생합니다.
- SIGCONT 시그널을 받으면 다시 실행될 수 있습니다.
2-5. 프로세스 상태 모니터링하는 방법
2-5-1. PS 명령어
- 많이 사용 하는 옵션 : ps -aux
-

- USER: 프로세스를 실행하는 사용자의 이름입니다.
- PID: 프로세스 ID. 시스템에서 각 프로세스를 구별하는 고유한 번호입니다.
- %CPU: 프로세스가 사용하는 CPU 시간의 비율입니다. 이 값은 CPU 사용률을 나타냅니다.
- %MEM: 시스템 RAM에서 프로세스가 사용하는 메모리의 비율입니다.
- VSZ: Virtual Set Size. 프로세스가 사용하는 가상 메모리의 크기(KB 또는 MB)입니다.
- RSS: Resident Set Size. 프로세스가 사용하는 실제 물리 메모리의 크기(KB 또는 MB)입니다.
- TTY: 프로세스가 연결된 터미널(Terminal)을 나타냅니다. 터미널이 없는 경우에는 '?'로 표시될 수 있습니다.
- STAT: 프로세스의 상태를 나타내는 코드입니다. 예를 들어, 'S'는 대기(sleeping) 상태, 'R'은 실행(running) 상태 등을 나타냅니다.
- R: Running 또는 Runnable. 프로세스가 현재 실행 중이거나 실행을 위해 준비가 되어 있음을 의미합니다.
- S: Sleeping. 프로세스가 인터럽트 가능한 수면 상태에 있음을 의미합니다. 즉, 특정 이벤트를 기다리고 있는 상태이며 시그널을 받으면 깨어날 수 있습니다.
- D: Uninterruptible Sleep (보통 IO). 프로세스가 디스크 입출력과 같은 작업을 기다리며 인터럽트할 수 없는 수면 상태에 있음을 의미합니다. 이 상태의 프로세스는 시그널을 받아도 깨어나지 않습니다.
- T: Stopped. 프로세스가 일시 중지되었거나 추적(디버깅) 중임을 의미합니다.
- Z: Zombie. 프로세스가 종료되었지만, 부모 프로세스가 아직 그 종료 상태를 회수하지 않은 상태를 말합니다.
- I: Idle. 주로 커널 쓰레드가 대기 상태에 있을 때 사용되며, 사용자 공간의 작업이 없는 상태입니다.
- <: High priority. 프로세스가 높은 우선 순위를 갖고 있음을 나타냅니다.
- N: Low priority. 프로세스가 낮은 우선 순위를 갖고 있음을 나타냅니다.
- L: Pages locked in memory. 실시간 작업에 사용됩니다.
- s: Session leader. 프로세스가 세션의 리더임을 의미합니다.
- l: Multi-threaded. 프로세스가 멀티 쓰레드를 갖고 있음을 나타냅니다.
- +: Foreground process. 프로세스가 포그라운드 프로세스 그룹에 있음을 의미합니다.
- START: 프로세스가 시작된 시간입니다.
- TIME: 프로세스가 지금까지 사용한 총 CPU 시간입니다.
- COMMAND: 프로세스를 시작한 명령어 또는 실행 파일의 이름입니다.
2-5-2. TOP 명령어
- 3초(기본값)동안 수집한 리눅스 프로세스 정보를 지속적으로 제공하는 도구
- 가장 CPU를 많이 사용하는 프로세스를 화면의 맨 위에 배치
- 화면 상단에는 시스템 상태의 요약 정보를 제공
- htop은 좀 더 나은 인터페이스를 제공 (스크롤, full 커맨드 라인 정보 제공)

top 실행 화면 
htop 실행 화면 2-5. 문제가 있는 프로세스 종료 방법
- 주로, kill 명령을 통해 프로세스를 종료 관련 시그널을 전송
ex) kill [-signal] pid - 주요 시그널

- SIGTERM [15] : 실행을 완전하게 종결하라는 요청. 프로세스가 시그널 수신(처리/차단) 가능
- SIGKILL [9] : 차단 불가능하며, 프로세스를 커널 수준에서 종료. 프로세스가 시그널을 수신할 수 없음
- SIGINT [2] : 터미널에서 ctrl+c입력시 전송. 프로세스가 시그널 수신(처리/차단) 가능
- - kill -15로 종료 해보고, kill -9를 시도하는 것을 권장
2-6. 프로세스 관리 - proc 파일 시스템
- ps 명령어나 top 명령어를 실행했을때 리눅스가 커널 정보를 가져올 때 참조하는 파일
- 커널이 시스템 상태와 관련한 다양한 정보를 노출 시키는 가상 파일 시스템
- 실제 파일이 존재하지 않음. 파일 사이즈 0
- 파일을 읽을 때 실시간으로 내용이 생성됨
- 프로세스 정보 외에도 커널이 관리하는 다양한 상태 정보와 통계값을 제공
- "프로세스와 관련된 정보"
- /proc/PID/cmdline: 특정 PID(프로세스 ID)를 가진 프로세스가 시작될 때 사용된 명령어 라인을 표시합니다.
- /proc/PID/environ: 프로세스의 환경변수 리스트를 제공합니다.
- /proc/PID/fd: 프로세스에 의해 열린 모든 파일 디스크립터를 나타내는 디렉토리입니다. 각 파일 디스크립터에 대한 심볼릭 링크가 포함되어 있습니다.
- /proc/PID/exe: 실행 중인 프로세스의 실행 파일에 대한 심볼릭 링크입니다. 이 링크를 통해 현재 실행 중인 프로그램을 찾거나 시작할 수 있습니다.
- /proc/PID/stat: 프로세스의 상태, 메모리 사용량, 스케줄링 정보 등 전반적인 프로세스 상태 정보가 포함되어 있습니다. 사람이 직접 읽기에는 복잡하므로 일반적으로 ps 명령어로 더 읽기 쉬운 형태로 정보를 조회합니다.
- /proc/self: 현재 실행 중인 프로세스를 가리키며, 프로세스가 자신의 정보에 접근할 때 사용됩니다.
- "프로세스와 관계 없는 시스템 정보"
- /proc/cpuinfo: 시스템의 CPU에 대한 상세 정보를 포함합니다.
- /proc/meminfo: 메모리 사용량, 사용 가능한 메모리 등 메모리 관리와 관련된 정보를 제공합니다.
- /proc/diskstats: 디스크 I/O 통계와 관련된 정보를 포함하며, 각 논리 디스크 장치에 대한 데이터가 포함됩니다.
- /proc/net: 네트워크 인터페이스, 연결, 라우팅 테이블 등 네트워크 스택에 관한 정보를 포함합니다.
- /proc/version: 리눅스 커널의 버전, 컴파일 시간, 컴파일러 정보 등을 표시합니다.
- /proc/uptime: 시스템이 부팅된 이후로부터 경과된 시간을 초 단위로 표시합니다.
- /proc/cmdline: 부팅 시 커널에 전달된 부트 옵션을 나타냅니다.
- /proc/kmsg: 커널 로깅 메시지를 포함하며, 시스템 로그를 읽는 데 사용됩니다.
2-7. 프로세스 관리 - 주기적인 실행 작업 관리
- 크론(cron)은 유닉스 기반 시스템에서 시간 기반의 작업 스케줄링을 위해 사용되는 도구입니다. 주로 반복적인 작업을 자동화하기 위해 사용됩니다.
- 크론 작업을 관리하는 데몬은 crond이며, 시스템 부팅 시 자동으로 시작됩니다.
- 크론은 crontab이라는 테이블을 사용하여 작업 스케줄을 관리합니다.
- systemd에 의해 해당 디렉토리 내부의 스크립트 파일들이 주기적으로 실행됩니다.
📢 /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, /etc/cron.monthly - crontab 관리 명령어
- crontab -e : 현재 사용자의 crontab 파일을 편집합니다. 이때 기본 텍스트 편집기가 열립니다.
- crontab -l : 현재 사용자의 crontab 파일 내용을 출력하여 보여줍니다.
- crontab -r : 현재 사용자의 crontab 파일을 삭제합니다.
- crontab -e USER_ID : 시스템 관리자(root 사용자)가 다른 사용자의 crontab 파일을 편집합니다.
- crontab 설정
- 분(0-59) 시(0-24) 일(1-31) 월(1-12) 요일(0-6) 명령
- 예) * * * * * command : 매 1분 마다 명령을 실행
- 예) 0 * * * * command : 매 1시간 마다 명령을 실행
- 예) 0 0 * * * command : 매 1일 마다 명령을 실행
- 예) 0 2 * * * command : 매일 새벽 2시에 명령을 실행
- 예) 0 2 * * 6 command : 매주 토요일 새벽 2시마다 명령을 실행
- 참고
- * 는 모든 것과 일치
- 하나의 정수는 정확히 그 값과 일치
- - 기호는 분리된 두 정수 범위 값과 일치
- 범위 값 다음에는 단계 값이 포함 (예, 1-10/2)
- , 로 분리된 범위 목록은 나열된 값중 하나와 일치
3. 로깅 (리눅스 로깅 이해, syslog 등)
- 적절한 크기 관리 및 만료 설정이 있어야 Disf Full과 같은 문제가 발생하지 않는다
3-1. 전형적인 리눅스 로그 관리 시스템 syslog
- IETF 표준 로깅 프로토콜(RFC 5424)을 따르는 포괄적인 로깅 시스템
- 개발자에게 로그 파일을 작성하는 메커니즘을 제공
- 시스템 관리자에게 로깅 통제권을 제공
- 시스템 관리자는 소스(facility), 중요도(severity level)에 따라 메시지 정렬, 다양한 목적지로 경로를 전환 및 내용을 변경
- syslog 데몬 변경 : syslogd à rsyslogd (syslog의 호환을 유지하면서 기능 확장)
- 로그 메시지 확인
- cat, grep, less, awk (일반적인 텍스트 처리 도구 사용)
- cat /var/log/syslog
- 로그 형식 : 타임스탬프, 호스트명, 프로세스 이름[PID], 메시지 페이로드

3-2. 개선된 로그 관리 방식 systemd의 journal
- 압축된 바이너리 형태로 로그 메시지를 저장 (로그를 보려면 journalctl 명령어 사용)
- journalctl 명령어
- -u 플래그를 써서 특정 서비스 유닛에 해당 하는 로그만 확인
journalctl -u ssh - -f (--follow)는 메시지를 실시간으로 출력
journalctl -f - 디스크에서 저널 크기 확인
journalctl --disk-usage - 특정 바이너리에서 최근 100개의 항목 확인
journalctl -n 100 /usr/sbin/sshd - 부팅 목록 확인
journalctl --list-boots - 로그를 특정 부트 세션에 제한 (바로 이전 세션의 ssh 로그 확인)
journalctl -b -1 -u ssh
- -u 플래그를 써서 특정 서비스 유닛에 해당 하는 로그만 확인
- journalctl 명령어
- 메세지 속성을 자동으로 인덱싱하여 검색 최적화
- systemd journal 환경설정

- 예를 들어 위 파일에서 Storage 옵션에는 다음과 같이 구성할 수 있다
- auto :
- 기본값. 데이터는 디스크에 저장 (재시작해도 로그 유지).
- /var/log/journal/ 디렉토리에 로그 저장. 디렉토리 생성은 하지 않음
- volatile :
- 저널을 메모리에만 저장.
- persistent :
- 저널을 /var/log/journal/ 디렉토리에 로그 저장.
- 디렉토리가 없는 경우 새로 생성
- none : 저널링 진행하지 않음
- auto :
3-3. syslog의 확장판 rsyslog (Rocket Fast System for Log processing)
- rsyslog 환경설정 /etc/syslog.conf 또는 /etc/rsyslog.d/ 디렉토리 내 .conf 파일

- 원격 서버로 로그를 보낼 경우 포트는 514번 포트를 사용하며 UDP, TCP 방식으로 전송이 가능
- 아래의 포맷을 가지고 어떤 서비스가 어떠한 상황일 때 어디로 로그를 보낼 지 설정합니다

rsyslog.conf의 포맷
3-3-1. facility : 어떤 서비스인지
facility Description * 모든 `facility`와 모든 심각도(severity)의 메시지를 나타냅니다 (단, `facility`에 '*' 사용은 일반적이지 않습니다) daemon 시스템 데몬에 의해 발생되는 메시지입니다 cron cron 작업 스케줄러에 의해 발생되는 메시지입니다 kern 커널에서 발생하는 메시지입니다 authpriv 보안과 관련된 인증 메시지, 예를 들어 패스워드 변경과 같은 개인정보와 관련된 메시지입니다 syslog syslogd 프로세스 자체에 의해 발생하는 메시지입니다 user 사용자 레벨에서 생성된 일반적인 프로세스의 메시지입니다 local0 ~ local7 사용자 또는 시스템 관리자가 특정 애플리케이션 또는 프로세스에 할당하여 사용하는 사용자 정의 메시지입니다 3-3-2. priority : 어떤 상황일 때
priority Description * 모든 상황 emerg 시스템이 사용 불가능한(unusable) 상태 alert 즉각적인 조치가 필요한 상황 crit 하드웨어 등의 심각한 오류가 발생한 상황 (critical condition) err 일반적인 에러/오류가 발생한 상황 warning 경고 메시지 notice 에러/오류는 아니지만 관리자의 조치가 필요한 상황 info 의미 있는 정보 관련 메시지 debug 디버깅용 메시지 3-3-3. action : 어디로 로그를
action Description host 메시지를 원격 호스트의 syslog 서비스로 전송합니다. 일반적으로 @hostname 형식을 사용합니다 user 지정된 사용자의 스크린으로 메시지를 보냅니다. 여러 사용자에게 메시지를 보내려면 사용자 이름을 쉼표로 구분하여 나열할 수 있습니다 file 메시지를 지정된 파일로 저장합니다. 이는 로그 파일의 경로로 지정됩니다 - 예를 들어 아래와 같은 규칙은 auth와 authpriv 퍼실리티에 대한 모든 긴급성 수준의 로그를 /var/log/auth.log에 기록하라는 의미입니다
auth,authpriv.* /var/log/auth.log3-3-4. 커스텀 규칙 만들기, 조건문 적용 if then

- 예를 들어 아래와 같은 커스텀 규칙은 로그 메시지(msg) 내용에 "UFw"라는 문자열이 포함되어 있을 경우 해당 메시지를 /var/log/ufw.log 파일에 기록하라는 의미입니다.
:msg, contains, "UFW" /var/log/ufw.log- 아래와 같이 if then 문법을 적용시킬 수도 있습니다
if $msg contains 'UFW' then /var/log/ufw.log # 또 다른 예시, 둘이 같은 동작을 함 :programname, isequal, "sshd" /var/log/ssh.log # or if $programname == 'sshd' then /var/log/ssh.log3-4. rsyslog와 systemd journal의 관계
- 로그 수집은 systemd journald 데몬이 메인으로 관리
- 로그 파일은 rsyslog를 통해서, rsyslog.conf 내용에 따라 /var/log에 만들어짐
- 로그 메시지 생성 과정
- 이벤트/메시지 생성: 시스템이나 응용 프로그램에서 발생하는 이벤트는 로그 메시지로 생성됩니다. 이것은 시스템 호출, 사용자 작업, 오류, 경고 등 다양한 활동을 포함할 수 있습니다.
- /dev/log: 이것은 UNIX 시스템에서 로그 메시지를 수집하기 위한 표준 로깅 인터페이스입니다. 다양한 시스템 프로세스와 서비스는 이 UNIX 소켓 파일을 통해 systemd-journald 데몬에 로그 메시지를 보냅니다.
- systemd-journald: systemd의 로깅 컴포넌트인 journald는 /dev/log로부터 메시지를 받아서 처리합니다. journald는 메시지를 분류하고, 필요한 경우 추가 정보를 추가하며, 그것을 자체적인 저널(로그 데이터베이스)에 저장합니다.
- rsyslogd: rsyslogd는 전통적인 로그 데몬으로, systemd-journald에 의해 처리되고 저장된 로그 메시지를 받습니다. rsyslogd는 로그 메시지를 더욱 정교하게 필터링하고, 형식화하며, 다양한 대상(예: 로그 파일, 원격 서버, 데이터베이스 등)으로 전송합니다.
- 로그 파일: rsyslogd는 로그 메시지를 파일 시스템에 있는 하나 이상의 로그 파일에 기록합니다. 예를 들어, /var/log/syslog, /var/log/auth.log, /var/log/mail.log 등과 같은 특정 파일에 로그를 저장할 수 있습니다.
- journalctl: journalctl은 systemd-journald에 의해 저장된 저널을 조회하기 위한 명령줄 도구입니다. 사용자는 journalctl을 사용하여 시스템 로그를 검색하고, 필터링하며, 출력할 수 있습니다.
3-5. 리눅스 로그 파일 관리 유틸리티 - logrotate
- 복잡한 로그 관리를 직접 할 필요 없이 logrotate 유틸리티를 통해 수행할 수 있다
- logrotate는 모든 리눅스 배포판의 표준 로그 관리 유틸리티이다
- 설정 파일은 /etc/logrotate.conf 에 위치해있다
- /etc/logrotate.d/ 디렉토리에 있는 파일들을 실행한다
- 주요 옵션
- compress : 현재 버전이 아닌 모든 log 파일들을 압축
- daily, weekly, monthly : 지정된 일정대로 로그 파일들을 로테이션
- delaycompress : 현재와 가장 최근 버전을 제외한 모든 버전을 압축
- endscript : prerotate나 postrotate 스크립트의 끝을 표시
- errors emailaddr : 지정된 이메일로 오류 알림 메시지를 보냄
- missingok : 로그 파일이 존재하지 않는 경우에 오류처리 하지 않음
- notifempty : 로그 파일이 비어 있으면 로테이트 하지 않음
- copytruncate : 로그 데이터를 새로운 파일로 카피하고, 기존 파일을 비움.
(장점: 로그 파일을 새로 열 필요가 없음 → 예를 들어 nginx에서 로그 관련 파일 이름을 수정할 필요가 없음, 단점: 로그가 큰 경우에는 오랜 시간이 걸릴 수 있음) - postrotate : 로그 로테이션이 완료된 후에 실행될 스크립트.
(예, 앱에 시그널을 보내서 파일을 새로 여는 작업 진행) - prerotate : 로그 파일의 변경 전 실행될 스크립트
- sharedscripts : 로그 파일이 여러개 있어도 (prerote, postrotate는 한번만 실행)
- rotate n : 최대 n개 버전의 로그 파일을 유지
- size logsize : 로그파일이 logsize 크기를 넘어선 경우 로테이션
- /etc/cron.daily에 의해 기본적으로 logrotate는 매일 실행이 됩니다

- /etc/logrotate.d/ 디렉토리 예시
# nginx /var/log/nginx/*.log { daily missingok rotate 14 compress delaycompress notifempty create 0640 www-data adm sharedscripts prerotate if [ -d /etc/logrotate.d/httpd-prerotate ]; then \ run-parts /etc/logrotate.d/httpd-prerotate; \ fi endscript postrotate invoke-rc.d nginx rotate > /dev/null 2>&1 endscript } # mongoDB /var/log/mongodb/mongod.log { su root root daily size 300M rotate 7 missingok compress delaycompress notifempty create 664 ubuntu ubuntu sharedscripts postrotate sudo /bin/kill -SIGUSR1 $(pgrep mongod) endscript }3-6. 대규모 로그 관리
- 서비스의 규모가 커짐에 따라 서버에 직접 접속해서 로그를 확인하는 것은 어려워짐
- 오토 스케일링 구성을 한 경우는 서버가 동적으로 생성 및 삭제가 됨
- 단순히 모으기만 해서는 대용량의 데이터를 효과적으로 관리하기 힘듦
- 여러가지 오픈소스 도구 및 SaaS 서비스들이 존재
- ELK 스택
- ElasticSearch, Logstash, Kibana
- 충분한 기능을 제공 (간편하게 로그 검색, 각종 차트 기능을 이용해 성능 분석 도구로 활용)
- 요청이 많을 경우 효율을 위해 버퍼 레이어(RabitMQ, AWS SQS, Kafka 등) 구성이 필요
- 관리 및 운영 비용은 단점
→ 관리형 ElasticSearch 서비스, SaaS형 솔루션인 logz.io 등 사용
→ 최신 로그만 저장하여 사용 (예, 한달 치 로그만 유지). 이전 데이터는 필요시 로딩

- 서비스형
- Splunk, Sumo Logic, Loggly, Amazon CloudWatch Logs
→ 간편히 사용 가능. 운영 인력이 적은 경우 좋은 선택
→ 비용을 고려해서 꼭 필요한 로그만 저장
- Splunk, Sumo Logic, Loggly, Amazon CloudWatch Logs
- 중앙 집중형 로그 관리 아키텍쳐

4. 네트워크 관리 (iproute2, DNS)
4-1. iproute2
- 네트워크 환경 설정이나 상태 확인을 위한 도구
이전 : net-tools (ifconfig, route, arp, netstat) → 유지보수, 성능, 구현의 비효율성 등 문제 - ip명령 + ss명령
- ip 명령: 라우팅을 포함한 일상적인 네트워크 환경설정을 위한 도구.
예) ip확인 : ip addr - ss 명령: 네트워크 소켓의 상태를 확인하는 도구. netstat를 거의 대체한 것.
예) 80포트 사용중인 프로세스 확인: sudo ss -tulpn | grep 80
- ip 명령: 라우팅을 포함한 일상적인 네트워크 환경설정을 위한 도구.
- 유용한 ip 명령
- 네트워크 인터페이스 확인: ip link
- IP 주소 확인: ip addr
- 인터페이스 활성화: ip link set eth0 down, ip link set eth0 up
- eth0 인터페이스에 IP 주소 추가 : ip addr add 192.0.2.11/24 dev eth0
- 라우팅 룰 추가: ip route add default via 192.0.2.1
- 라우팅 테이블 확인 : ip route
net-tools iproute2 ifconfig (interface list) ip link ifconfig (ip configuration) ip addr ifconfig (interface stats) ip -s link route ip route arp ip neigh brctl addbr ip link add ... type bridge brctl addif ip link set master netstat ss netstat -M conntrack -L netstat -g ip maddr netstat -i ip -s link netstat -r ip route iptunnel ip tunnel ipmaddr ip maddr tunctl ip tuntap (since iproute-2.6.34) (none) for interface rename ip link set dev OLDNAME name NEWNAME brctl bridge (since iproute-3.5.0) 4-2. DNS (Domain Name System)
- 계층 구조를 가지는 분산 데이터베이스 형태
- 자신이 알고 있는 컴퓨터들에 대한 데이터를 저장하고 있는 사이트가 서로 협력해 데이터를 공유
- 일반적인 웹사이트 접속 시나리오
- 사이트 이름을 입력
- 웹 브라우저는 DNS resolver 라이브러리를 호출해 상응하는 주소를 검색
- A 레코드를 위한 쿼리를 만들어 네임서버에 요청
- 네임 서버는 A 레코드를 반환
- 브라우저는 IP 주소를 통해 타겟 호스트에 TCP 접속을 진행
- 호스명과 IP 주소를 매핑하는 방법
- /etc/hosts 파일 사용

- 가장 오래되고 간단한 방법
- IP 주소와 이름을 명세
- 외부에 이름을 공개하지 않도록 매핑하는데도 사용 (예, 내부 모니터링 시스템)
- /etc/resolv.conf 파일 사용

- DNS 구성
- DNS 도메인들과 이름 검색을 위해 사용할 네임서버 주소를 나열
- 네임서버가 여러 개 존재할 때는 위에서부터 시도
- 설정 옵션
- nameserver: 네임서버 주소
- search: 자동으로 찾을 도메인 주소 입력 à abcde를 abced.ap-northeast-2.compute.internal로 검색
- /etc/hosts 파일 사용
- AWS에서 DNS 정보 수정 방법
/etc/resolv.conf 수정은 적용되지 않음
1. /etc/dhcp/dhclient.conf à supersede domain-name-servers xxx.xxx.xxx.xxx, xxx.xxx.xxx.xxx;
2. /etc/netplan/99-custom-dns.yaml 수정
https://repost.aws/ko/knowledge-center/ec2-static-dns-ubuntu-debian
고정 DNS 서버로 EC2 인스턴스 구성
재부팅하는 동안 유지되는 정적 DNS 서버 항목을 사용하여 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 구성하고 싶습니다.
repost.aws
- DNS 데이터베이스에 질의 하는 도구
- nslookup, dig, host, drill, delv
- nslookup, host 는 간단하고 출력이 보기 좋음
- dig, drill은 구체적인 내용 제공
- nslookup, dig, host, drill, delv
마무리
- 분량 조절 실패~★
- 하다보니 계속 찾아보게 되네요 껄껄껄
- 그래도 운영체제는 내용이 너무 많아서 이제 겨우 새발의 피인 것 같지만;; 조금이라도 늘긴했으니 그거면 됐습니다~!

그럼 다들 열공하세요~!
반응형'데브옵스 > 운영체제' 카테고리의 다른 글
BPF 기반 리눅스 성능 분석 (2) 2024.02.05 리눅스 시스템 성능 분석 (4) 2024.02.04 리눅스 운영의 기초 : 스크립트 및 설정 자동화 (2) 2024.01.29 리눅스 운영의 기초 : 파일시스템, 소프트웨어 및 사용자 관리 (2) 2024.01.22 이전글이 없습니다.댓글