중간의 관련 연산들을 테이프에 기록하고, 역전파(backward)를 수행했을 때 기울기가 계산된다
import tensorflow as tf
x = tf.Variable([3.0, 4.0])
y = tf.Variable([1.0, 2.0])
# 진행되는 모든 연산들을 기록
with tf.GradientTape() as tape:
z = x + y
loss = tf.math.reduce_mean(z)
dx = tape.gradient(loss, x) # loss가 scalar이므로 계산 가능
print(dx)
TensorFlow에서는 변수가 아닌 상수라면 기본적으로 기울기를 측정하지 않는다. (not watched)
또한, 변수라고 해도 학습 가능하지 않으면 (not trainable) 자동 미분을 사용하지 않는다
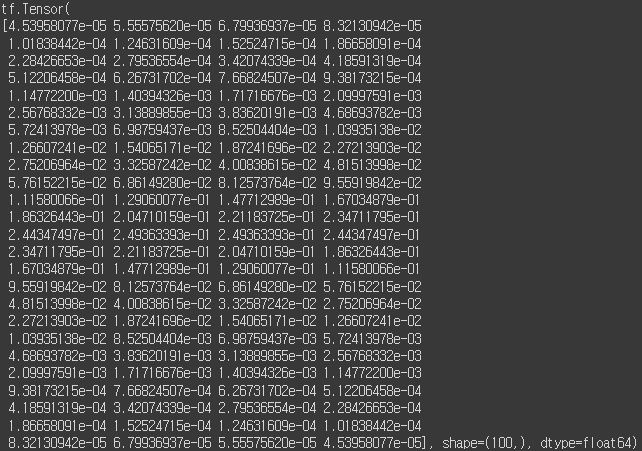
x = tf.linspace(-10, 10, 100)
with tf.GradientTape() as tape:
tape.watch(x) # constant이므로, watch() 함수 호출 필요
y = tf.nn.sigmoid(x)
dx = tape.gradient(y, x)
print(dx)
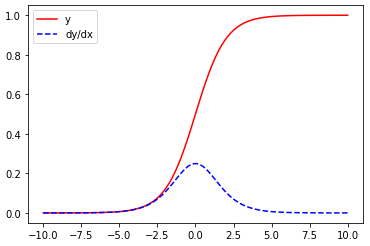
도함수도 그래프로 출력이 가능하다
import matplotlib.pyplot as plt
plt.plot(x, y, 'r', label="y")
plt.plot(x, dx, 'b--', label="dy/dx")
plt.legend()
plt.show()
2. 뉴런부터 깊은 모델 만들기 - 텐서플로우
기존에 사용하였던 날씨 데이터를 그대로 사용
# 데이터 세트 다운로드
!git clone https://github.com/ndb796/weather_dataset
%cd weather_dataset
# 라이브러리 불러오기(Load Libraries)
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
이미지를 불러올 때 어떤 방법(회전, 자르기, 뒤집기 등)을 사용할 것인지 명시할 수 있다
이후에 flow()를 이용하여 실질적으로 데이터를 불러올 수 있다
어떤 데이터를 사용할 것인지, 배치 크기(batch size), 데이터 셔플(shuffle) 여부 등을 명시한다. next() 함수를 이용하여 numpy array 형태로 데이터를 배치 단위로 얻을 수 있다.
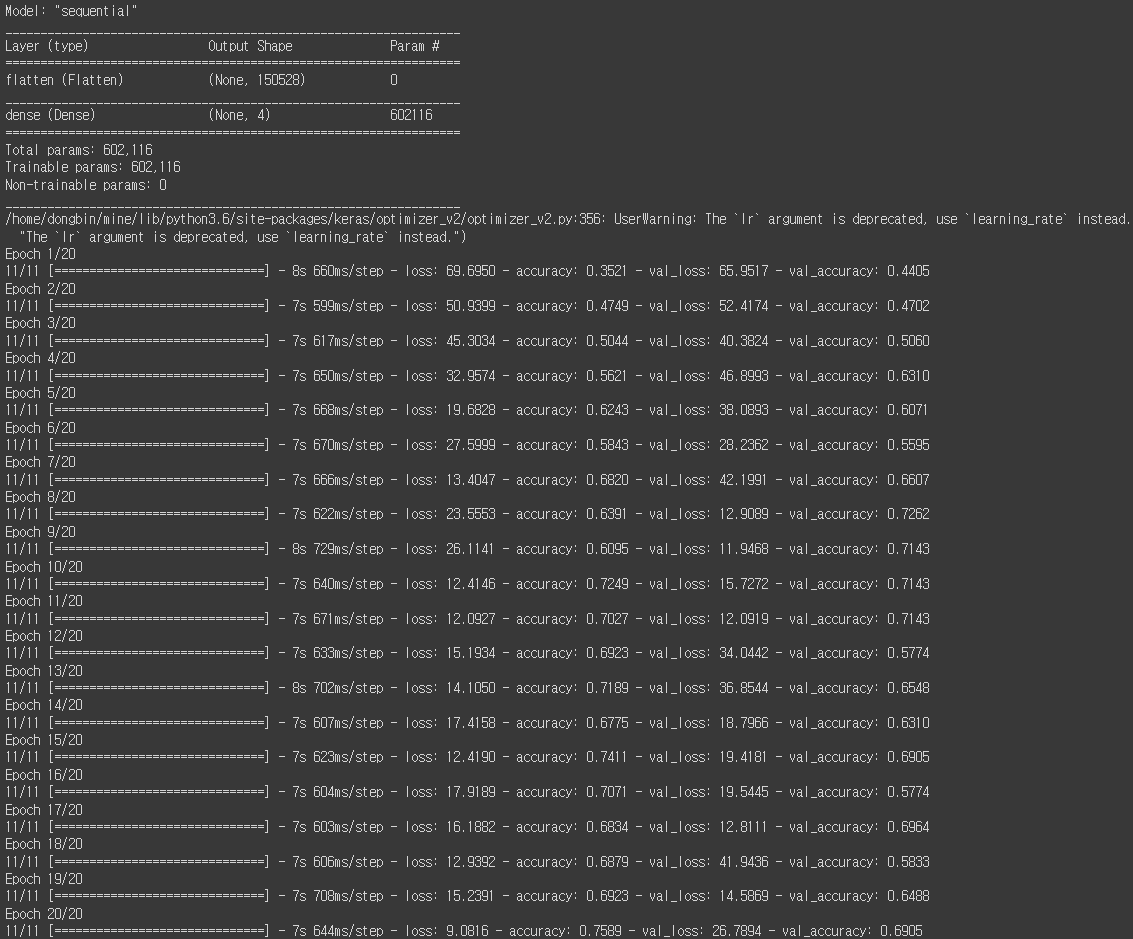
model_1 = get_model_1()
model_1.summary()
learning_rate = 0.01
# 학습 준비 단계(compile)
model_1.compile(
optimizer=optimizers.SGD(lr=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 학습 수행
history = model_1.fit(
train_flow,
epochs=20,
validation_data=val_flow
)
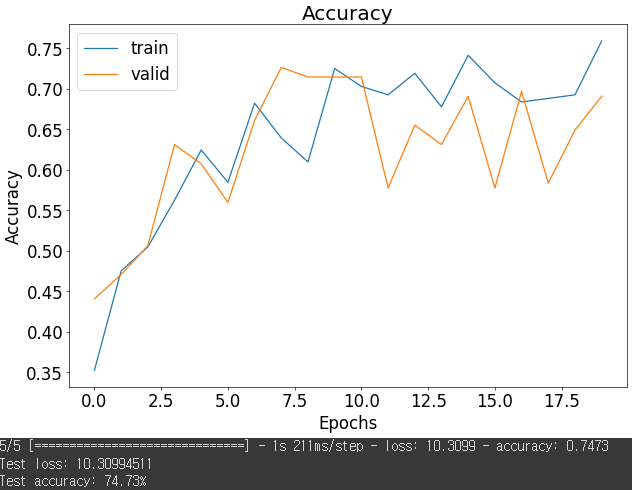
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.title('Accuracy')
plt.legend(['train', 'valid'])
plt.show()
# 학습된 모델 테스트
test_history = model_1.evaluate(test_flow)
test_loss, test_accuracy = test_history
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
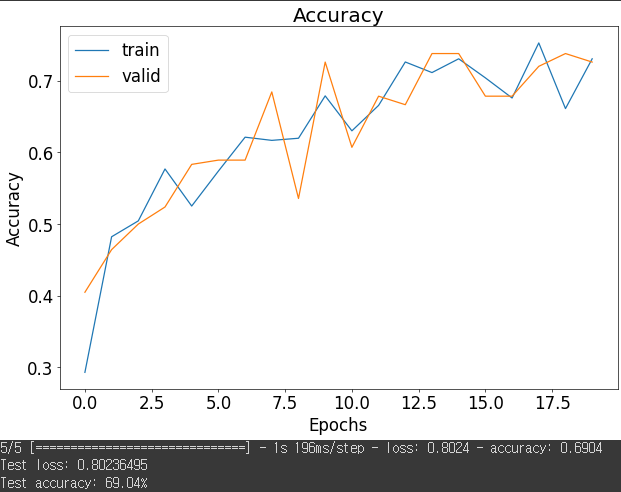
모델 2의 학습결과
model_2 = get_model_2()
model_2.summary()
learning_rate = 0.01
# 학습 준비 단계(compile)
model_2.compile(
optimizer=optimizers.SGD(lr=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 학습 수행
history = model_2.fit(
train_flow,
epochs=20,
validation_data=val_flow
)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.title('Accuracy')
plt.legend(['train', 'valid'])
plt.show()
# 학습된 모델 테스트
test_history = model_2.evaluate(test_flow)
test_loss, test_accuracy = test_history
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
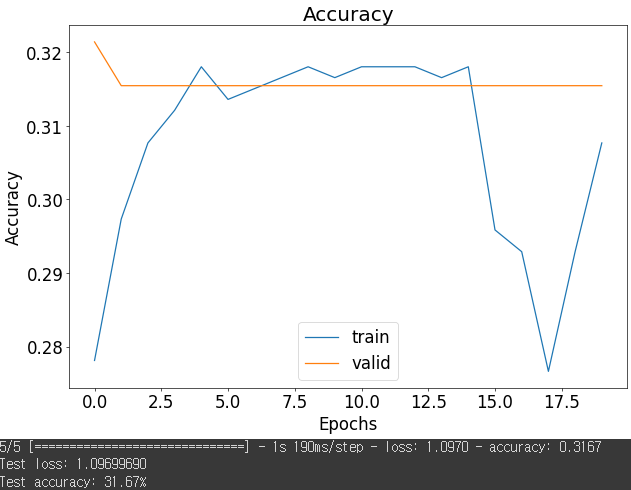
모델 3의 학습결과
model_3 = get_model_3()
model_3.summary()
learning_rate = 0.01
# 학습 준비 단계(compile)
model_3.compile(
optimizer=optimizers.SGD(lr=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 학습 수행
history = model_3.fit(
train_flow,
epochs=20,
validation_data=val_flow
)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.title('Accuracy')
plt.legend(['train', 'valid'])
plt.show()
# 학습된 모델 테스트
test_history = model_3.evaluate(test_flow)
test_loss, test_accuracy = test_history
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
더 많은 파라미터와 깊은 네트워크를 사용했다고 정확도가 항상 올라가는 것은 아니다
learning rate를 잘 조절해가면서 수정해가야 정확도를 향상 시킬 수 있다
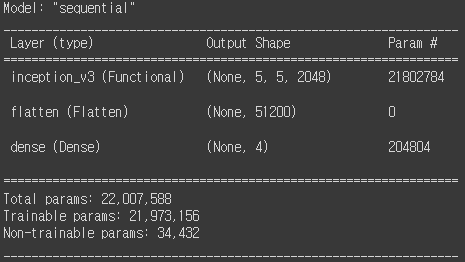
3. 이미지 날씨 분류 모델 - 텐서플로우
같은 날씨 데이터 모델 세트를 사용
# 데이터 세트 다운로드
!git clone https://github.com/ndb796/weather_dataset
%cd weather_dataset
# 라이브러리 불러오기(Load Libraries)
from tensorflow.keras.applications import InceptionV3
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
learning_rate = 0.001
# 학습 준비 단계(compile)
model.compile(
optimizer=optimizers.SGD(lr=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
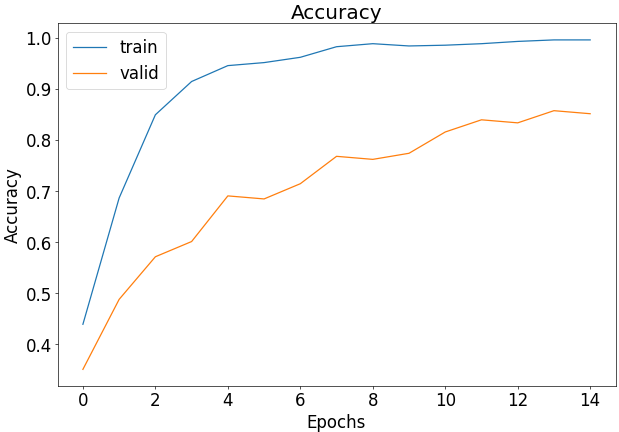
# 학습 수행
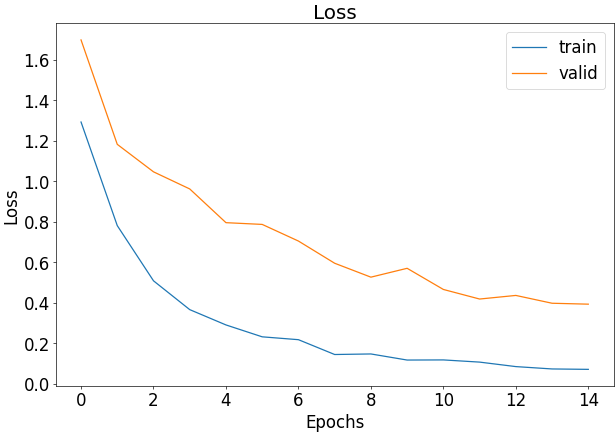
history = model.fit(
train_flow,
epochs=15,
validation_data=val_flow
)