- 데이터 로더, 모델 실습, 로깅2024년 02월 21일 07시 13분 11초에 업로드 된 글입니다.작성자: 재형이반응형
- 가보자 가보자
1. 데이터 로더 (Data Loader)
- 데이터 세트가 항상 내가 원하는 형식으로 되어있지 않기 때문에 데이터를 불러올 때 특정한 형식으로 불러올 수 있어야 한다
- 이때 커스텀 데이터 로더를 구성해서 이용할 수 있다
- 다음 같은 구성으로 데이터 로더를 만들 수 있다

1-1. 꽃 분류 데이터 세트 불러오기
- 꽃 분류 데이터 세트 구성
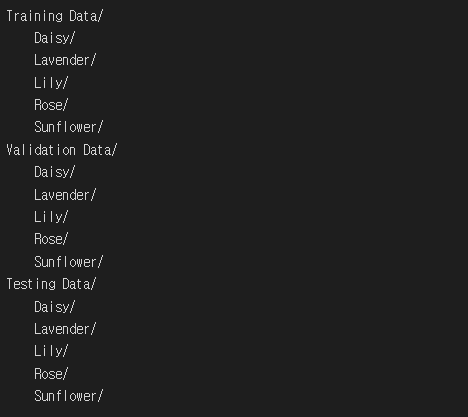
- 커스텀 데이터 로더 구성하기
import torch from torchvision import transforms from torch.utils.data import DataLoader from PIL import Image from IPython.display import display import matplotlib.pyplot as plt import numpy as np import os import random import glob import xml.etree.ElementTree as elemTree !git clone https://github.com/ndb796/flower_classification_dataset class CustomFlowerDataset(torch.utils.data.Dataset): def __init__(self, root, transform=None): self.root = root self.transform = transform # 루트(root) 경로에 존재하는 모든 클래스(class) 폴더 확인 self.directories = glob.glob(os.path.join(self.root, "*")) self.dataset = [] self.class_names = [] self.index = 0 # 각 폴더는 클래스(class) 이름에 해당 for directory in self.directories: # 클래스 이름(class name) 추가 class_name = directory.split('/')[-1] self.class_names.append(class_name) # 해당 클래스의 모든 이미지를 확인하며 image_paths = glob.glob(os.path.join(directory, "*")) for image_path in image_paths: # 이미지 경로(image path)와 레이블 번호(index) 기록 self.dataset.append((image_path, self.index)) self.index += 1 def __len__(self): return len(self.dataset) def __getitem__(self, idx): image_path, label = self.dataset[idx] image = Image.open(image_path).convert("RGB") if self.transform: image = self.transform(image) label = torch.tensor(label) return image, label- 학습 데이터
train_transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) train_dataset = CustomFlowerDataset( root="flower_classification_dataset/Training Data", transform=train_transform ) train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True) print(f"학습 데이터 개수: {len(train_dataset)}") iterator = iter(train_dataloader) imgs, labels = next(iterator) # 배치 안에서 첫 번째 데이터 시각화 imshow(imgs[0]) print(f"Class name: {train_dataset.class_names[labels[0].item()]}")
- 검증 데이터
val_transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_dataset = CustomFlowerDataset( root="flower_classification_dataset/Validation Data", transform=val_transform ) val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=True) print(f"검증 데이터 개수: {len(val_dataset)}") iterator = iter(val_dataloader) imgs, labels = next(iterator) # 배치 안에서 첫 번째 데이터 시각화 imshow(imgs[0]) print(f"Class name: {val_dataset.class_names[labels[0].item()]}")
- 테스트 데이터
test_transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) test_dataset = CustomFlowerDataset( root="flower_classification_dataset/Testing Data", transform=test_transform ) test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False) print(f"테스트 데이터 개수: {len(test_dataset)}") iterator = iter(test_dataloader) imgs, labels = next(iterator) # 배치 안에서 첫 번째 데이터 시각화 imshow(imgs[0]) print(f"Class name: {test_dataset.class_names[labels[0].item()]}")
2. 사전 학습 모델 사용하기
- 다양한 사전 학습 모델을 사용해보자
2-1. 데이터 세트 불러오기
- 날씨 데이터 세트 로드
!git clone https://github.com/ndb796/weather_dataset %cd weather_dataset # 라이브러리 불러오기(Load Libraries) import torch import torchvision import torchvision.transforms as transforms import torchvision.models as models import torchvision.datasets as datasets import torch.optim as optim import torch.nn as nn import torch.nn.functional as F from torch.utils.data import random_split import matplotlib.pyplot as plt import matplotlib.image as image import numpy as np # 데이터 세트 불러오기(Load Dataset) transform_train = transforms.Compose([ transforms.Resize((224, 224)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5] ) ]) transform_val = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5] ) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5] ) ]) train_dataset = datasets.ImageFolder( root='train/', transform=transform_train ) dataset_size = len(train_dataset) train_size = int(dataset_size * 0.8) val_size = dataset_size - train_size train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size]) test_dataset = datasets.ImageFolder( root='test/', transform=transform_test ) train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=8, shuffle=True) val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False) test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=8, shuffle=False) # 데이터 시각화(Data Visualization) plt.rcParams['figure.figsize'] = [12, 8] plt.rcParams['figure.dpi'] = 60 plt.rcParams.update({'font.size': 20}) def imshow(input): # torch.Tensor => numpy input = input.numpy().transpose((1, 2, 0)) # undo image normalization mean = np.array([0.5, 0.5, 0.5]) std = np.array([0.5, 0.5, 0.5]) input = std * input + mean input = np.clip(input, 0, 1) # display images plt.imshow(input) plt.show() class_names = { 0: "Cloudy", 1: "Rain", 2: "Shine", 3: "Sunrise" } # load a batch of train image iterator = iter(train_dataloader) # visualize a batch of train image imgs, labels = next(iterator) out = torchvision.utils.make_grid(imgs[:4]) imshow(out) print([class_names[labels[i].item()] for i in range(4)])
2-2. 사전 학습된 ResNet-50
- 사전 학습된(pre-trained) 모델(model)을 이용하여 가지고 있는 데이터 세트에 대한 학습이 가능하다
- 네트워크의 마지막에 FC 레이어를 적용하여 클래스 개수를 일치시킨다
model = models.resnet50(pretrained=True) # print(model) # 모델 정보 출력 num_features = model.fc.in_features model.fc = nn.Linear(num_features, 4) # transfer learning model = model.cuda() inputs = imgs.cuda() targets = labels.cuda() outputs = model(inputs) print(outputs.shape)2-3. 사전 학습된 DenseNet-121
model = models.densenet161(pretrained=True) # print(model) # 모델 정보 출력 num_features = model.classifier.in_features model.classifier = nn.Linear(num_features, 4) # transfer learning model = model.cuda() inputs = imgs.cuda() targets = labels.cuda() outputs = model(inputs) print(outputs.shape)2-4. 사전 학습된 VGG-19
model = models.vgg19(pretrained=True) # print(model) # 모델 정보 출력 num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(num_features, 4) # transfer learning model = model.cuda() inputs = imgs.cuda() targets = labels.cuda() outputs = model(inputs) print(outputs.shape)2-5. 사전 학습된 EfficientNet-b0
model = models.efficientnet_b0(pretrained=True) # print(model) # 모델 정보 출력 num_features = model.classifier[1].in_features model.classifier[1] = nn.Linear(num_features, 4) # transfer learning model = model.cuda() inputs = imgs.cuda() targets = labels.cuda() outputs = model(inputs) print(outputs.shape)2-6. 사전 학습된 AlexNet
model = models.alexnet(pretrained=True) # print(model) # 모델 정보 출력 num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(num_features, 4) # transfer learning model = model.cuda() inputs = imgs.cuda() targets = labels.cuda() outputs = model(inputs) print(outputs.shape)3. Optimzier에 따른 모델 정확도 평가
- 딥러닝 프레임워크는 다양한 최적화 방법(optimizer)을 제공한다
- 동일한 모델을 여러 최적화 방법으로 학습하여, 정확도 비교 분석을 진행할 수 있다
- 파이토치에서는 SGD, Adagrad, RMSprop, Adadelta, Adam와 같은 다양한 Optimizer를 제공한다
3-1. 사전 준비
# 필요한 라이브러리 불러오기 import torch import torch.nn as nn from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader import torch.optim as optim import time import matplotlib.pyplot as plt batch_size = 128 learning_rate = 0.001 # 딥러닝 모델 정의 # 간단히 4개의 레이어로 구성된 깊은 뉴럴 네트워크(deep neural network)를 사용 class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.layer1 = nn.Linear(784, 256) self.layer2 = nn.Linear(256, 128) self.layer3 = nn.Linear(128, 64) self.layer4 = nn.Linear(64, 10) def forward(self, x): x = torch.flatten(x, start_dim=1) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) return x # 학습 데이터 세트 불러오기 # MNIST 데이터 세트를 이용 -> Train: 60,000 / Test: 10,000 train_dataset = datasets.MNIST( root="./data", train=True, transform=transforms.ToTensor(), download=True ) test_dataset = datasets.MNIST( root="./data", train=False, transform=transforms.ToTensor(), download=True ) train_dataloader = DataLoader(train_dataset, batch_size=batch_size) test_dataloader = DataLoader(test_dataset, batch_size=batch_size) # 모델 및 Optmizer 초기화 optimizer_names = ["SGD", "Adagrad", "RMSprop", "Adadelta", "Adam"] models = [Model().cuda() for i in range(5)] optimizers = [ optim.SGD(models[0].parameters(), lr=learning_rate), optim.Adagrad(models[1].parameters(), lr=learning_rate), optim.RMSprop(models[2].parameters(), lr=learning_rate), optim.Adadelta(models[3].parameters(), lr=learning_rate), optim.Adam(models[4].parameters(), lr=learning_rate) ] # 로깅(logging) train_losses = [[] for _ in range(5)] test_losses = [[] for _ in range(5)] train_accuracies = [[] for _ in range(5)] test_accuracies = [[] for _ in range(5)]3-2. 학습(Training)
- 각 최적화 방법(optimizer)에 따른 학습 결과를 확인한다
criterion = nn.CrossEntropyLoss(reduction="mean") n_epoch = 20 log_step = 100 # 각 실험(experiment)에 대하여 for exp in range(5): # 현재의 실험 설정에 대하여 출력 print("=================================================") print(f"[Experiment {exp + 1}]") print(f"Optimizer: {optimizer_names[exp]}") print(f"Batch size: {batch_size}") print(f"Learning rate: {learning_rate}") print(f"Total number of epochs: {n_epoch}") start_time = time.time() # 현재 실험에서 사용할 모델(model)과 최적화 방법(optimizer)을 선택 model = models[exp] optimizer = optimizers[exp] # 반복(epoch)하여 학습 수행 for epoch in range(n_epoch): print(f"[Epoch: {epoch + 1}]") # 학습(training) model.train() total = 0 running_loss = 0.0 running_corrects = 0.0 for i, batch in enumerate(train_dataloader): # 현재 배치의 이미지와 레이블 꺼내기 inputs, targets = batch inputs, targets = inputs.cuda(), targets.cuda() optimizer.zero_grad() outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, targets) loss.backward() # 기울기 계산 optimizer.step() # 계산된 기울기를 이용해 가중치 업데이트 total += targets.shape[0] running_loss += (loss.item() * targets.shape[0]) running_corrects += torch.sum(preds == targets.data) train_loss = running_loss / total train_accuracy = running_corrects / total print(f'Train loss: {train_loss:.6f}, train accuracy: {train_accuracy * 100.:.2f}%') # 테스트(test) model.eval() total = 0 running_loss = 0.0 running_corrects = 0.0 for i, batch in enumerate(test_dataloader): # 현재 배치의 이미지와 레이블 꺼내기 inputs, targets = batch inputs, targets = inputs.cuda(), targets.cuda() # 학습 없이 정확도를 평가하므로 기울기(gradient) 추적 제외 with torch.no_grad(): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, targets) total += targets.shape[0] running_loss += (loss.item() * targets.shape[0]) running_corrects += torch.sum(preds == targets.data) test_loss = running_loss / total test_accuracy = running_corrects / total print(f'Test loss: {test_loss:.6f}, test accuracy: {test_accuracy * 100.:.2f}%') # 로깅(logging) train_losses[exp].append(train_loss) test_losses[exp].append(test_loss) train_accuracies[exp].append(train_accuracy) test_accuracies[exp].append(test_accuracy) print(f"Elapsed time: {time.time() - start_time:.2f} seconds.")3-3. 학습 결과 시각화하기
- 각 최적화 방법(optimizer)에 따른 학습 결과를 시각화할 수 있다
- 학습 정확도(train accuracy)와 학습 손실(train loss)를 시각화하면 다음과 같다
markers = [".", "v", "^", "s", "*"] plt.figure(figsize=(20, 10)) epochs = [[i] for i in range(1, 21)] plt.subplot(1, 2, 1) for exp in range(5): train_accuracy = [x.cpu() for x in train_accuracies[exp]] plt.plot(epochs, train_accuracy, marker=markers[exp], label=optimizer_names[exp]) plt.xlabel("Epoch") plt.ylabel("Train Accuracy") plt.legend() plt.subplot(1, 2, 2) for exp in range(5): plt.plot(epochs, train_losses[exp], marker=markers[exp], label=optimizer_names[exp]) plt.xlabel("Epoch") plt.ylabel("Train Loss") plt.legend() plt.show()
- 테스트 정확도(test accuracy)와 테스트 손실(test loss)를 시각화하면 다음과 같다
markers = [".", "v", "^", "s", "*"] plt.figure(figsize=(20, 10)) epochs = [[i] for i in range(1, 21)] plt.subplot(1, 2, 1) for exp in range(5): test_accuracy = [x.cpu() for x in test_accuracies[exp]] plt.plot(epochs, test_accuracy, marker=markers[exp], label=optimizer_names[exp]) plt.xlabel("Epoch") plt.ylabel("Test Accuracy") plt.legend() plt.subplot(1, 2, 2) for exp in range(5): plt.plot(epochs, test_losses[exp], marker=markers[exp], label=optimizer_names[exp]) plt.xlabel("Epoch") plt.ylabel("Test Loss") plt.legend() plt.show()
4. 로깅 - WandB
- WandB를 이용한 학습 및 평가 과정 로깅(Logging)
- WandB는 기계학습/딥러닝 개발자를 위한 종합적인 보조 도구다
- 가장 대표적인 기능으로는 우리가 딥러닝 모델을 학습할 때 학습 과정에 대해서 로깅(logging)을 진행해 준다. 그래서 손실(loss) 값의 감소하는 형태를 쉽게 파악할 수 있다.
- 특히 WandB는 팀 단위로 실험 결과를 추적할 수 있도록 해주기 때문에, 웹 상에서 보다 편리하게 분석이 가능하다
- WanDB 공식 홈페이지: https://wandb.ai/
Home
The Weights & Biases MLOps platform helps AI developers streamline their ML workflow from end-to-end.
wandb.ai
4-1. WandB 예제 코드 사용해 보기
- API Key를 발급 받아서 사용해야 한다
- Settings: https://wandb.ai/settings
Sign In with Auth0
wandb.ai
!pip install wandb !wandb login- PyTorch 공식 문서에서 제공하는 MNIST 학습 코드를 가져와 실행해 보자
import wandb from types import SimpleNamespace import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.optim.lr_scheduler import StepLR class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: break def test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 # wandb에 기록할 테스트 이미지들 tested_images = [] with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() # wandb에 현재 배치에 포함된 첫 번째 이미지에 대한 추론 결과 기록 tested_images.append( wandb.Image(data[0], caption=f'Predicted: {pred[0].item()}, Ground-truth: {target[0]}' )) test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) # wandb에 로깅 진행 wandb.log({ "Tested Images": tested_images, "Test Average Loss": test_loss, "Test Accuarcy": 100. * correct / len(test_loader.dataset) }) def main(args): # wandb 프로젝트 초기화 wandb.init(project='wandb-mnist-example', entity='dongbin_na') # wandb에 하이퍼파라미터 configuration 정보 기록 wandb.config.update(args) use_cuda = not args.no_cuda and torch.cuda.is_available() torch.manual_seed(args.seed) device = torch.device("cuda" if use_cuda else "cpu") train_kwargs = {'batch_size': args.batch_size} test_kwargs = {'batch_size': args.test_batch_size} if use_cuda: cuda_kwargs = {'num_workers': 1, 'pin_memory': True, 'shuffle': True} train_kwargs.update(cuda_kwargs) test_kwargs.update(cuda_kwargs) transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) dataset1 = datasets.MNIST('../data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('../data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs) model = Net().to(device) # wandb에서 학습할 모델 정보 추적 wandb.watch(model) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) for epoch in range(1, args.epochs + 1): train(args, model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step() if args.save_model: torch.save(model.state_dict(), "mnist_cnn.pt")# Training settings args = SimpleNamespace() args.batch_size = 64 # input batch size for training args.test_batch_size = 1000 # input batch size for testing args.epochs = 14 # number of epochs to train args.lr = 1 # learning rate args.gamma = 0.7 # learning rate step gamma args.no_cuda = False # disables CUDA training args.dry_run = False # quickly check a single pass args.seed = 1 # random seed args.log_interval = 100 # how many batches to wait before logging training status args.save_model = False # for Saving the current Model main(args)- WandB 로그 확인하기
- 코드를 실행한 폴더에도 wandb 관련 log 폴더가 생성된다
- 실행할 때마다 한 번의 run 폴더가 생긴다
- 기본적으로 wandb 서버에 학습할 때의 로그 데이터가 모두 업로드 된다
- 웹 상에서 즉시 확인할 수 있다는 측면에서 편리하다

5. 딥러닝 도구 툴 및 논문 보는 법
5-1. 다양한 딥러닝 프레임워크
- 파이토치(PyTorch)
- 페이스북(Facebook) AI 연구팀이 개발하였다
- 텐서를 NumPy 배열과 유사하게 조작할 수 있다
- 프레임워크를 배우기 쉽고, 빠르게 구현할 수 있다
- 하지만, 입문자가 바로 사용하기에는 어려움이 있다
- 딥러닝 분야에서 텐서플로우보다 점유율이 높아졌다
- 파이토치 튜토리얼: https://tutorials.pytorch.kr/
파이토치(PyTorch) 한국어 튜토리얼에 오신 것을 환영합니다!
파이토치(PyTorch) 한국어 튜토리얼에 오신 것을 환영합니다. 파이토치 한국 사용자 모임은 한국어를 사용하시는 많은 분들께 PyTorch를 소개하고 함께 배우며 성장하는 것을 목표로 하고 있습니다.
tutorials.pytorch.kr
- 텐서플로우(TensorFlow)
- 텐서보드(Tensorboard)를 이용해 학습 과정을 시각화할 수 있다
- 데이터 플로우 그래프를 사용하여 딥러닝 학습 과정을 정의할 수 있다
- 버전 1과 버전 2로 나누어져 사용자 입장에서 헷갈릴 수 있다
- 텐서플로우 튜토리얼: https://www.tensorflow.org/tutorials
TensorFlow Core
ML 초보자 및 전문가를 위해 TensorFlow를 사용하는 방법을 알아보는 완벽한 엔드 투 엔드 예시입니다. Google Colab에서 튜토리얼을 사용해 보세요. 설정이 필요하지 않습니다.
www.tensorflow.org
- 케라스(Keras)
- 초보자가 사용하기 쉽다
- 비교적 간단한 문제를 해결할 때, 빠르게 적용해 볼 수 있다
- 일관된 API를 사용하여, 동일한 데이터 세트에 대하여 다양한 기계학습을 적용할 수 있다
- 딥러닝 모델 아키텍처를 변경하는 구체적인 작업이 어려울 수 있다
- 오류가 발생했을 때, 원인을 파악하기 어려울 수 있다
- 케라스 튜토리얼: https://blog.keras.io/category/tutorials.html
The Keras Blog - Tutorials
Tue 21 March 2017 By Francois Chollet In Tutorials. This is a step by step guide to start running deep learning Jupyter notebooks on an AWS GPU instance, while editing the notebooks from anywhere, in your browser. This is the perfect setup for deep learnin
blog.keras.io
5-2. 다양한 딥러닝 로깅(Logging) 및 디버깅(Debugging) 도구
- 텐서보드(Tensorboard)
- 텐서보드는 기계 학습 실험 과정에서 필요한 시각화(visualization) 기능을 제공한다
- 손실(loss), 정확도(accuracy)와 같은 평가 지표 정보를 추적할 수 있다
- 학습 과정에 따른 가중치(weight), 편향(bias) 등의 히스토그램(histogram)을 볼 수 있다
- 이미지(image), 오디오(audio) 등의 데이터를 출력할 수 있다
- 텐서보드 홈페이지: https://www.tensorflow.org/tensorboard
TensorBoard | TensorFlow
TensorBoard: TensorFlow의 시각화 툴킷
www.tensorflow.org
- WandB (Weight & Bias)
- WandB는 기계 학습 실험 과정에서 필요한 시각화(visualization) 기능을 제공한다
- 간단한 회원가입, 로그인, 인증 과정으로 손쉽게 사용할 수 있다
- TensorBoard와 유사한 기능을 제공한다
- 각 프로젝트(project) 및 실험(experiment)을 기준으로 로그 정보를 나누어 저장할 수 있다
- WandB 홈페이지: https://wandb.ai/
Home
The Weights & Biases MLOps platform helps AI developers streamline their ML workflow from end-to-end.
wandb.ai
5-3. 논문 검색 방법
- 아카이브(Arxiv)
- 아카이브(Arxiv)에서는 다양한 딥러닝 분야의 출판 전 논문을 확인할 수 있다
- 다양한 논문을 무료로 다운로드하여 빠르게 읽어 볼 수 있다
- 아카이브 링크: https://arxiv.org
arXiv.org e-Print archive
arxiv.org
- Paperswithcode
- 논문의 핵심 내용, 실험 결과 스크린샷, 코드에 대한 정보를 빠르게 확인할 수 있다
- 다양한 논문의 성능 비교 결과를 한 눈에 보여준다
- Paperswithcode 링크: https://paperswithcode.com/
Papers with Code - The latest in Machine Learning
Papers With Code highlights trending Machine Learning research and the code to implement it.
paperswithcode.com
반응형'인공지능 > 프레임워크 or 라이브러리' 카테고리의 다른 글
자전거 대여량 예측 - 선형 회귀, 군집 모델 (클러스터링) 실습 (4) 2024.03.15 제조 데이터의 분류기 실습 (0) 2024.03.14 Image Captcha 라이브러리 (Library) (4) 2024.02.20 대량의 데이터 다루기, 누락된 데이터 처리, 클래스 활용 (0) 2024.02.20 의사 결정 트리, 랜덤 포레스트, SVM, 선형 회귀 (4) 2024.02.15 이전글이 없습니다.댓글