3: 약간 눈내림, 약간 비 + 천둥번개 + Scattered 구름, 약간의 비 + Scattered 구름
4: 소나기 + 우박 + 천둥번개 + 안개, 눈 + 짙은 안개
온도 - temperature in Celsius
체감온도 - "feels like" temperature in Celsius
습도 - relative humidity
풍량 - wind speed
미가입 - number of non-registered user rentals initiated
가입 - number of registered user rentals initiated
렌탈수 - number of total rentals (Dependent Variable)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('exercise2.csv')
df.head()
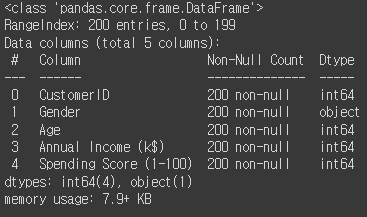
df.shape로 총 행의 갯수와 열의 갯수를 파악해보자
10886개의 행과 12개의 열로 이루어져있다는 것을 알 수 있다
df.describe()로 데이터들이 어떻게 분포되어 있는지 확인해보자
우리가 구하고자 하는 값인 count를 기준으로 시각화해보자
각 항목들 별로 시각화
nrows, ncols = 2, 5
fig, axs = plt.subplots(nrows=nrows, ncols=ncols)
fig.set_size_inches(20,8)
for i in range(nrows):
for j in range(ncols):
attr = i * ncols + j + 1
sns.histplot(x = df.columns[attr], data = df, ax=axs[i][j])
히트맵으로 시각화
sns.heatmap(df.corr())
이제 데이터를 분할해보고 모델을 불러와서 학습시켜보자
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_log_error
Y = df['count']
X = df.drop(['datetime', 'count'], axis=1,inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42)
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
y_pred = lr_model.predict(X_test)
mean_squared_log_error(y_test, y_pred)
# 2.2538764933380931e-29
거의 0에 수렴하는 오차값이 나왔다...? 띠용? 성능 무엇?
사실 데이터 전처리를 제대로 하지 않고 학습을 진행했기 때문에 성능이 좋게 나온 것이다...
어떤 값이 영향을 가장 많이 주었는지 살펴보면 회원인지 아닌지가 가장 영향을 많이 준 것을 확인 할 수 있다. 하지만 count = registered + casual 이기 때문에 사실 registered랑 casual은 독립 변수가 아니다. 이 값들 또한 우리가 예측해야할 값들이기 때문에 drop 시켜줘야 한다