실습 목표
VGGNet을 사용하여 이미지를 학습하고 10개의 카테고리를 갖는 이미지를 분류하는 이미지 분류기를 생성한다. (데이터셋: CIFAR )
Pre-training 모델의 사용방법을 이해한다.
문제 정의
주요 코드
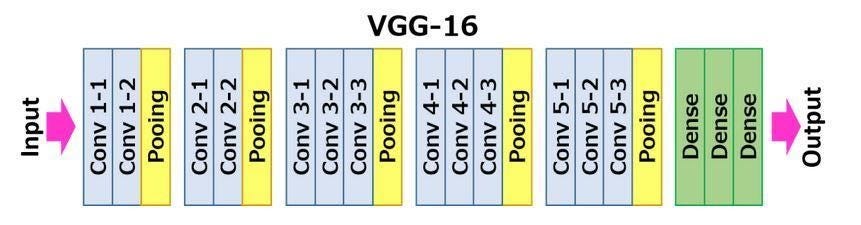
1. VGGNet
# Model
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Sequential(
nn.Linear(512 * 1 * 1, 360),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(360, 100),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(100, 10),
)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
# 'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
return nn.Sequential(*layers)2. Pretrained model
from torchvision import models
vgg16 = models.vgg16(pretrained=True)
vgg16.to(DEVICE)
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(vgg16.classifier.parameters(), lr = LEARNING_RATE, momentum=0.9)CIFAR Classifier(VGGNet)
CIFAR 데이터셋을 사용하여 이미지에 포함된 object가 무엇인지 분류하는 이미지 분류기를 생성해봅니다
[Step1] Load libraries & Datasets
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch.utils.data import DataLoader
from torch import nn
from torchvision import datasets
from torchvision.transforms import transforms
from torchvision.transforms.functional import to_pil_image[Step2] Data preprocessing
불러온 이미지의 증강을 통해 학습 정확도를 향상시키도록 합니다.
RandomCrop
RandomHorizontalFlip
Normalize
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
train_img = datasets.CIFAR10(
root = 'data',
train = True,
download = True,
transform = transform,
)
test_img = datasets.CIFAR10(
root = 'data',
train = False,
download = True,
transform = transform,
)[Step3] Set hyperparameters
EPOCH = 10
BATCH_SIZE = 32
LEARNING_RATE = 1e-3
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using Device:", DEVICE)[Step4] Create DataLoader
train_loader = DataLoader(train_img, batch_size = BATCH_SIZE, shuffle = True)
test_loader = DataLoader(test_img, batch_size = BATCH_SIZE, shuffle = False)[Step5] Set Network Structure
# Model
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Sequential(
nn.Linear(512 * 1 * 1, 360),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(360, 100),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(100, 10),
)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
return nn.Sequential(*layers)[Step6] Create Model instance
model = VGG('VGG16').to(DEVICE)
print(model)
VGG(
[Step7] Model compile
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = LEARNING_RATE, momentum=0.9)[Step8] Set train loop
def train(train_loader, model, loss_fn, optimizer):
model.train()
size = len(train_loader.dataset)
for batch, (X, y) in enumerate(train_loader):
X, y = X.to(DEVICE), y.to(DEVICE)
pred = model(X)
# 손실 계산
loss = loss_fn(pred, y)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f'loss: {loss:>7f} [{current:>5d}]/{size:5d}')[Step9] Set test loop
def test(test_loader, model, loss_fn):
model.eval()
size = len(test_loader.dataset)
num_batches = len(test_loader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(DEVICE), y.to(DEVICE)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:8f}\n")[Step10] Run model
for i in range(EPOCH) :
print(f"Epoch {i+1} \n------------------------")
train(train_loader, model, loss, optimizer)
test(test_loader, model, loss)
print("Done!")CIFAR Classifier(Pretrained VGGNet)
ImageNet 데이터로 학습한 VGGNet을 사용하여 주어진 데이터 셋에서 사용할 수 있도록 Fine tuning 해봅니다
from torchvision import models
vgg16 = models.vgg16(pretrained=True)
vgg16.to(DEVICE)
print(vgg16)
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead. https://download.pytorch.org/models/vgg16-397923af.pth " to /root/.cache/torch/hub/checkpoints/vgg16-397923af.pth
vgg16.classifier[6].out_features = 10
for param in vgg16.features.parameters():
param.requires_grad = False
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(vgg16.classifier.parameters(), lr = LEARNING_RATE, momentum=0.9)
for i in range(EPOCH) :
print(f"Epoch {i+1} \n------------------------")
train(train_loader, vgg16, loss, optimizer)
test(test_loader, vgg16, loss)
print("Done!")