- 나는 할 수 있다
- 요즘 실습 위주라 코드만 막 올라가고 있긴 한데...ㅎ 몰라~
실습 목표
- VAE를 설계하고 학습시켜 이미지를 생성하는 모델을 만듭니다. (데이터셋: MNIST)
문제 정의
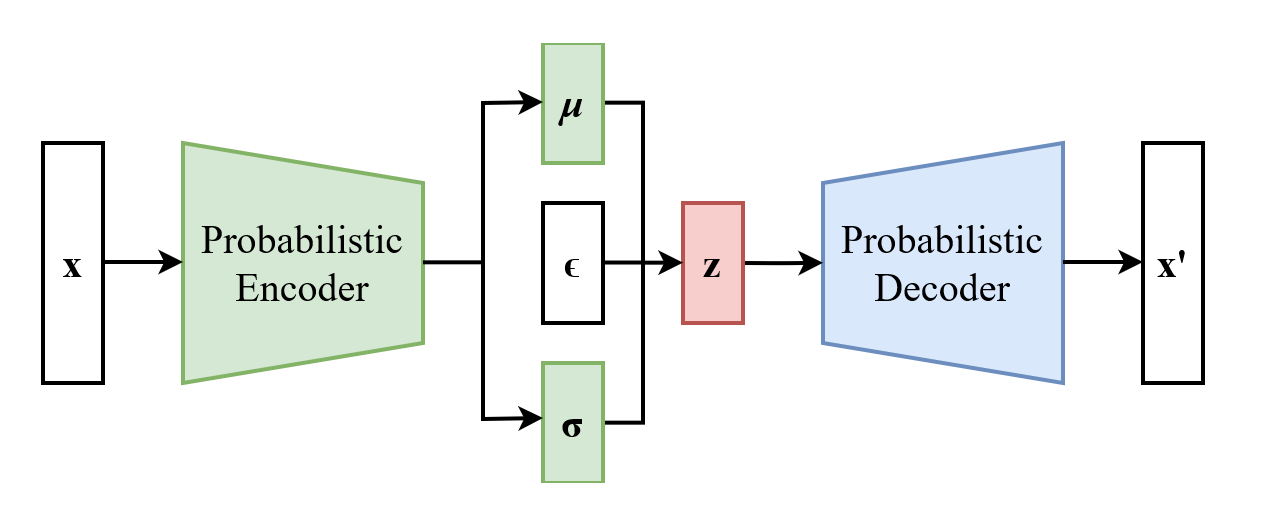
VAE
[Step1] Load libraries & Datasets
import numpy as np
import matplotlib.pyplot as plt
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torch.nn as nn
import torch.nn.functional as F
import torch
train_images = datasets.MNIST(
root= 'data',
train= True,
download= True,
transform= ToTensor()
)
test_images = datasets.MNIST(
root= 'data',
train= True,
download= True,
transform= ToTensor()
)
[Step2] Set hyperparameters
# 하이퍼파라미터 준비
EPOCH = 10
BATCH_SIZE = 64
LEARNING_RATE = 1e-3
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using Device:", DEVICE)
[Step3] Create DataLoader
train_loader = DataLoader(train_images, batch_size = BATCH_SIZE, shuffle = True)
test_loader = DataLoader(test_images, batch_size = BATCH_SIZE, shuffle = True)
[Step4] Set Network Structure (구조)
class VAE(nn.Module):
def __init__(self, latent_dim):
super(VAE, self).__init__()
self.flatten = nn.Flatten()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
)
self.fc_mu = nn.Linear(256, latent_dim)
self.fc_var = nn.Linear(256, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28 * 28),
nn.Sigmoid(),
)
def encode(self, x):
result = self.encoder(x)
mu = self.fc_mu(result)
var = self.fc_var(result)
return mu, var
def decode(self, z):
result = self.decoder(z)
return result
def reparameterize(self, mu, var):
std = torch.exp(var / 2)
eps = torch.randn_like(std)
return mu + (eps * std)
def forward(self, x):
x = self.flatten(x)
mu, var = self.encode(x)
z = self.reparameterize(mu, var)
out = self.decode(z)
return out, mu, var
[Step5] Create Model instance
model = VAE(10).to(DEVICE)
print(model)
- VAE(
(flatten): Flatten(start_dim=1, end_dim=-1)
(encoder): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=256, bias=True)
(3): ReLU()
)
(fc_mu): Linear(in_features=256, out_features=10, bias=True)
(fc_var): Linear(in_features=256, out_features=10, bias=True)
(decoder): Sequential(
(0): Linear(in_features=10, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=784, bias=True)
(5): Sigmoid()
)
)
[Step6] Model compile
def loss_function(recon_x, x, mu, var):
recon_loss = F.binary_cross_entropy(recon_x, x.view(-1, 28*28), reduction='sum')
kl_loss = -0.5 * torch.sum(1 + var - mu.pow(2) - var.exp())
return recon_loss + kl_loss
optimizer = torch.optim.Adam(model.parameters(), lr= LEARNING_RATE)
[Step7] Set train loop
def train(train_loader, model, loss_fn, optimizer):
model.train()
for batch, (X, y) in enumerate(train_loader):
X, y = X.to(DEVICE), y.to(DEVICE)
decoded, mu, var= model(X)
# 손실계산
loss = loss_fn(decoded, X, mu, var)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 결과 시각화
origin_data = X[:5].view(-1, 28*28).type(torch.FloatTensor)/255.
decoded_data = decoded[:5].view(-1, 28*28).type(torch.FloatTensor)/255.
f, axs = plt.subplots(2, 5, figsize=(5, 2))
for i in range(5):
img = np.reshape(origin_data.data.numpy()[i],(28, 28))
axs[0][i].imshow(img, cmap='gray')
axs[0][i].set_xticks(())
axs[0][i].set_yticks(())
for i in range(5):
img = np.reshape(decoded_data.to("cpu").data.numpy()[i], (28, 28))
axs[1][i].imshow(img, cmap='gray')
axs[1][i].set_xticks(())
axs[1][i].set_yticks(())
plt.show()
[Step8] Run Model
for i in range(EPOCH):
print(f"Epoch {i+1} \n------------------------")
train(train_loader, model, loss_function, optimizer)
