- Policy Iteration2024년 03월 31일 08시 23분 56초에 업로드 된 글입니다.작성자: 재형이반응형
- 벌써 오늘이 마지막 날이다
- 어제 조대협님의 대항로도 끝을 맺었고...
- 다시 리프레시할겸 계획을 세워야 겠다
- 구글 스터디잼 + AWS 자격증 + 사이드 프로젝트 + 독서 + 운동 +...ㅎ
- 나는 계속 매일 블로그를 올려볼 생각이다. 원래는 패스트캠퍼스 강의 남은걸로 진행할까 했는데 구글 스터디잼도 괜찮을 것 같다. 여튼 뭐가 됐든ㅎ
- 이전에는 벨류를 구하는 방법을 찾았으니, 이번에는 최적의 폴리시를 구하는 방법을 알아보자
- 이전과 같은 작은 MDP 문제를 사용해보자
- 작은 문제
- 작다는 것은 다음의 가짓수가 작은 것을 의미함
- A c t io n s p a c e
- S t a t e s p a c e
- T im e h o r iz o n
- M D P 를 알 때
- 𝑀𝐷𝑃 ≡ {𝑆, 𝐴, 𝑅, 𝑃, 𝛾}
- 𝑅, 𝑃 를 알 때
- 여기서 안 다는 것은 해보기도 전에 미리 아는 것
- 어떻게?
- 테이블 기반 방법론!
- & D y n a m ic P r o g r a m in g
- 작은 문제
Policy Iteration – policy improvement

- 이전에 구했었던 벨류 테이블이다
- 여기서 한칸을 greedy하게 움직이고, 그 다음 파이'로 움직인다고 했을 때
- greedy 정책: 학습하면서 얻은 가치 함수 중 가장 큰 값을 따라가는 것
- 파이'은 파이보다 낫다고 할 수 있을까?
- 현재 파이를 따라서 끝까지 움직인다고 했을 때 밸류는 -54.6이다
- 그리디하게 한칸을 움직이고, 이후 파이'를 따라 끝까지 움직이면? → -1 -49.7 = -50.7
- 즉 현재 파이보다 파이'이 낫다
- 𝝅 ′ > 𝝅
- 그러면 이 논리를 파이'에도 적용해보면 어떨까?
- 𝝅'', 𝝅''', ...
- 계속 더 좋은 파이가 나온다
- 이것을 계속해서 반복해본다면?
Policy Iteration – policy improvement
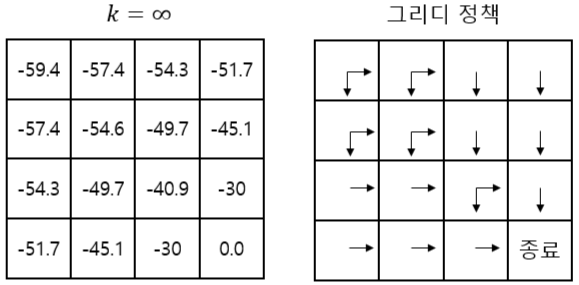
- 위와 같은 Greedy Policy가생성된다
- 우리는 지금 기존 정책 𝜋 보다 개선된, 더 나은 정책을 찾았다
- 즉, 정책 개선(policy improvement) 가 이루어졌다
- 이렇게 새로운 파이를 얻었으니, 다시 이를 평가할 수 있다. 우리가 저번에 했던 것처럼!(policy evaluation방법론 사용)
- 다음 둘을 계속해서 반복하면 계속해서 더 나은 정책이 만들어진다!!!
- Policy evaluation → iterative policy evaluation
- Policy improvement → greedy policy

- 아니 근데 이것을 무한대로 계속 반복하는 걸 중첩으로 해야하는데... 코드로 구현하면 중첩 for문을 무한대로...시간이 엄청 걸린다...

- 평가 부분을 꼭 수렴할때까지 해야할까? 어차피 크기 비교만 가능하면 되는거 아냐?

- k가 무한대일 때랑 k가 6일 때랑 어차피 크기만 비교하면 되는건데... 똑같은거 아녀? 어차피 그리디 정책인데;;
- 즉, 꼭 수렴할때까지 돌릴 필요가 없다는 것이다

- 이처럼 평가 부분을 간소화 할 수 있다
- 극단적으로 k=1 로 한 번의 업데이트만 하고 바로 greedy po licy를얻는다
- 이렇게 해도 최적 정책으로 수렴함이 알려져 있다
반응형'인공지능 > 강화학습' 카테고리의 다른 글
MDP를 알 때의 플래닝 (0) 2024.03.30 벨만 최적 방정식 (2) 2024.03.29 벨만 기대 방정식 (4) 2024.03.28 Markov Decision Process (4) 2024.03.27 Markov Process, Markov Reward Process (2) 2024.03.26 이전글이 없습니다.댓글