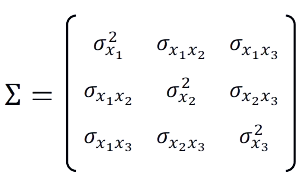import math
arr = [56, 93, 88, 72, 65]
mean = 0
for x in arr:
mean += x / len(arr)
variance = 0
for x in arr:
variance += ((x - mean) ** 2) / len(arr)
std = math.sqrt(variance)
print(f"평균: {mean:.2f}")
print(f"분산: {variance:.2f}")
print(f"표준 편차: {std:.2f}")
두 확률변수 𝑋와 𝑌의 공분산은 다음과 같이 정의된다 $Cov[X,Y] = E[(X - E[X])(Y - E[Y])]$
두 확률변수 𝑋와 𝑌의 상관 계수는 다음과 같이 정의된다 $\rho [X,Y] = \frac{Cov[X,Y]}{\sqrt{Var[X] \cdot Var[Y]}}$
상관계수($\rho$)는 항상 -1 이상 1 이하의 값을 가진다 $\rho$ = 1 : 완전 선형 양수(+) 상관관계 $\rho$ = -1 : 완전 선형 음수(-) 상관관계
4-4. 공분산 행렬 (Covariance Matrix)
다변수 확률변수를 행렬로 나타낼 수 있다.
하나의 데이터가 3개(d=3)의 원소를 가지는 벡터라고 할 때, 이러한 데이터가 N개 있을 경우 다음처럼 나타낼 수 있다
N x 3 행렬
위의 행렬을 공분산 행렬로 표현하면 상관관계를 알 수 있다
3개의 서로 다른 확률 변수의 모든 조합에 대하여, 공분산을 한꺼번에 표기할 수 있다
이를 공분산 행렬(covariance matrix)라고 한다
공분산 행렬 Σ는 다음과 같이 정의된다. (데이터 개수: 𝑁개, 특징의 수: 𝑑개일 때)
대각 성분(diagonal)은 각 확률변수의 분산이다.
비 대각 성분(off-diagonal)은 두 확률변수의 공분산이다
4-5. 공분산과 독립
$P_{XY} (x,y) = P_{X} (x) P_{Y} (y)$ 일 때 X와 Y가 독립 관계라고 할 수 있다.
결과적으로 𝑋와 𝑌가 독립이라면 다음의 공식이 성립한다 → 𝐸(𝑋𝑌) = 𝐸(𝑋)𝐸(𝑌)
이때 공분산 𝐶𝑜𝑣(𝑋,𝑌) = 𝐸(𝑋𝑌) − 𝐸(𝑋)𝐸(𝑌) = 0이다 → 두 확률 변수가 독립이라면, 공분산은 0이다
역은 성립하지 않는다 → 공분산이 0이라고 해서 두 확률 변수가 독립이라는 보장은 없다
4-6. 파이썬으로 공분산 계산
수학 성적과 영어 성적에 대하여 평균, 분산, 공분산, 상관계수를 계산해보자
import matplotlib.pyplot as plt
X = [97, 85, 26, 54, 76, 15, 33, 83, 88, 91]
Y = [100, 92, 31, 61, 83, 28, 57, 45, 92, 93]
plt.plot(X, Y, 'o')
plt.xlabel("Math")
plt.ylabel("English")
plt.show()
# 평균(mean) 계산
x_mean = 0
for x in X:
x_mean += x / len(X)
# 분산(variance) 계산
x_var = 0
for x in X:
x_var += ((x - x_mean) ** 2) / (len(X) - 1)
print(f"x_mean = {x_mean:.3f}, x_var = {x_var:.3f}")
# 평균(mean) 계산
y_mean = 0
for y in Y:
y_mean += y / len(Y)
# 분산(variance) 계산
y_var = 0
for y in Y:
y_var += ((y - y_mean) ** 2) / (len(Y) - 1)
print(f"y_mean = {y_mean:.3f}, y_var = {y_var:.3f}")
import numpy as np
np.set_printoptions(precision=3)
import math
# 공분산(covariance)
covar = 0
for x, y in zip(X, Y):
covar += ((x - x_mean) * (y - y_mean)) / (len(X) - 1)
print(f"Sample covariance: {covar:.3f}")
print("[Sample covariance (NumPy)]")
print(np.cov(X, Y))
# 상관 계수(correlation coefficient)
correlation_coefficient = covar / math.sqrt(x_var * y_var)
print(f"Correlation coefficient: {correlation_coefficient:.3f}")
print("[Correlation coefficient (NumPy)]")
print(np.corrcoef(X, Y))