- 신경망 성능 향상, 1D conv, Embedding (1)2024년 03월 07일 07시 24분 03초에 업로드 된 글입니다.작성자: 재형이반응형
- 볼펜 사야겠네;;
- 오늘은 예비군 작계 훈련이 있는 날이라 아침에 좀 느긋하게 작성하는 중이다
- 사실 마음이 싱숭생숭해서 집중이 잘 안됨;;ㅜㅜ 사춘긴가

짜증
1. 신경망의 성능을 높이기 위해 자주 사용하는 방법들
- 좋은 성능의 인공 신경망의 특징
- 일반화
: 미확인 데이터에 대해서도 예측을 잘 할 수 있어야 함 - 정확도
: 답변이 믿을만 해야 함 - 리소스 측면
: 컴퓨팅 자원을 효율적으로 사용해야 함 - 학습 속도 측면
: 학습 속도가 너무 느리면 곤란함
- 일반화
- 인공 신경망의 일반화를 위해서는 대표적으로 오버피팅을 막아야 한다
- 학습용 데이터를 늘림
- Early Stopping
- Regularization : L2, L1, Dropout 등
- 앙상블 모델
2. 다양한 Conv
- Convolution 연산은 단순히 이미지에만 적용시킬 수 있는 것이 아니다
- 텍스트를 Embedding하면 1차원이 나오는데 기존에 사용하던 2차원의 이미지와 달리 Conv1D를 사용할 수 있다
2-1. Conv 1D
- Text Classification with Conv1D

- Time series data with Conv1D
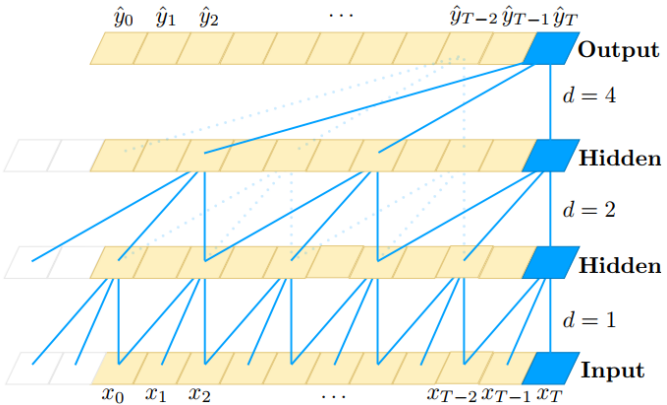
2-2. Dilated Convolution

- Dilated Convolution은 Convolutional layer에 또 다른 파라미터인 dilation rate를 사용
- dilation rate은 커널 사이의 간격을 정의합니다. dilation rate가 2인 3x3 커널은 9개의 파라미터를 사용하면서 5x5 커널과 동일한 시야(view)를 가집니다
- 동일한 계산 비용으로 더 넓은 시야를 제공합니다
2-3. Transposed Convolutions
- Convolution 연산이 특징을 추출해내는 것이였다면 Transposed Convolutions는 반대로 특징을 가지고 원본을 만들어내는 연산이다

- 이런 Convolutions 연산을 통해 출력된 Output이 있다
- 이것을 Transposed Convolutions을 통해 원본을 복구하기 위해서 Output을 살짝 변형해준 후에 Transposed Convolutions 연산을 진행해준다

- 이미지의 해상도를 높이거나 할 때 활용될 수 있겠다
3. Embedding
- 딥러닝에 학습시키기 위해서 정형•비정형 데이터가 가지는 특징을 그대로 보존하면서 벡터로 표현하는 것

- 그래프 같은 경우에는 노드끼리의 관계를 벡터로 표현할 수 있다

- 이 중에 Word Embedding을 중점으로 알아보자
3-1. 텍스트를 숫자로 표현하기 위한 방법

3-1-1. One Hot Vector
- 범주를 정하고 범주에 해당하는 단어가 포함 여부를 벡터로 나타냄
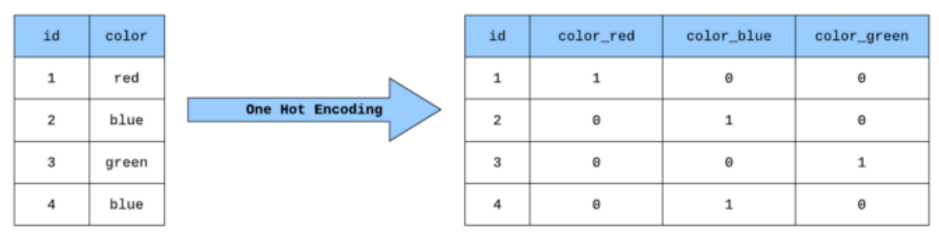
- 하지만 One Hot Vector는 원본의 특징을 표현할 수 없다
- 그리고 범주가 많아지면 데이터를 많이 차지하게 됨 → 비효율적
3-1-2. Bow (Bag of Words)
- 문장을 구성하는 단어들을 카테고리로 분류하고 해당 단어가 몇번 나왔는지를 기준으로 벡터로 표현하는 방법이다
- 사이킷런에서 기본적으로 제공해준다 → CountVectorizer

3-1-3. TF-IDF
- TF(Term Frequency)
- 단어가 문서에 나타난 횟수
- IDF(Inverse Document Frequency)
- 단어가 포함된 문서의 수의 역수


- 단어의 빈도수를 측정하는데, 자주 나오는 단어는 어떤 책의 특징을 나타낸다고 보기 힘들다
- 즉, 책의 특징을 나타낼 수 있는 단어들을 찾는 것이 목표이다
- 이 친구도 사이킷런에서 기본적으로 제공해준다 → TfidfVectorizer

반응형'인공지능 > 인공지능 기초' 카테고리의 다른 글
NLP (2) (0) 2024.03.09 Embedding (2), NLP (1) (2) 2024.03.08 VGGNet, GoogLeNet(Inception), ResNet, Transfer Learning (0) 2024.03.06 CNN 연산, Conv, Pooling, 컴퓨터 비젼 (0) 2024.03.05 분류 알고리즘, 회귀 알고리즘 (0) 2024.03.04 이전글이 없습니다.댓글