- NLP (2)2024년 03월 09일 11시 23분 57초에 업로드 된 글입니다.작성자: 재형이반응형
- 어제 조대협 강사님의 항로 1기 1주차 프로젝트 미팅을 하고 왔다
- 요즘들어 집에 있는게 편하고 친구들이 만나자고 해도 귀찮고 그랬었는데, 오랜만에 처음보는 사람들을 만나니 너무 신났다
- 역시 아무래도 나는 E가 맞는가보다
1. 텍스트 정제 (Cleaning)
- 모든 텍스트 마이닝의 첫 시작은 텍스트 정제부터 시작해야한다
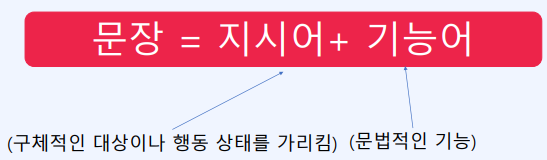
- 텍스트 정제 : 자연어를 단어 기준으로 구분하거나 형태소 기준으로 구분하는 것처럼 특징을 추출하기 용이한 형태로 바꾸는 것
- 텍스트 마이닝 : 자연어에서부터 특징을 추출하여 의미있는 정보들을 가져오는 것

텍스트 정제의 필요성 - 다양한 텍스트 정제 활동
- 대소문자 통일
- 문장부호/특수문자 제거
- 숫자제거
- 공백, 개행문자 제거
- 띄어쓰기 보정
- 품사분석 (Part of Speech tagging)
- 불용어 (stopword) 제거
- 토큰화
1-1. 토큰화
- 자연어를 어떤 단위로 살펴볼 것인가
- 어절: 문장 성분의 최소 단위로서 띄어쓰기의 단위
- 형태소: 의미를 가지는 요소로서는 더 이상 분석할 수 없는 가장 작은 말의 단위
- n-gram

1-2. 불용어
- 기능어는 문장에서 실질적인 의미를 별로 가지고 있지 않기 때문에 불용어로 간주하여 제거
- 영어: 관사, 전치사
- 한국어: 조사
1-3. 어근 동일화
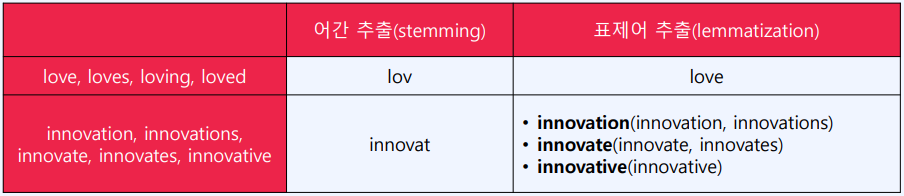
- 어간 추출 (stemming)
- 단어의 어미나 접두사, 접미사 등으로 해서 형태가 달라진 단어들을 형태소 분석을 통해 그 어간을 추출하여 동일한 단어로 간주하는 작업
- 표제어 추출 (lemmatization)
- 어간 추출의 단점 보완: 단어의 의미적 단위를 고려하지 않고 단어를 축약형으로 정리
1-4. 품사분석 (Part of Speech tagging)
- 브라운 말뭉치(Brown corpus) 기반
- 미국의 브라운 대학에서 구축, 87개의 표식 목록

- 국립국어원의 세종 말뭉치 사전에 기반

2. 텍스트 마이닝(Text Mining)
- 자연어 처리 기술을 활용하여 텍스트 데이터를 정형화하고, 특징을 추출하여 의미 있는 정보를 발견할
수 있도록 하는 기술

https://www.youtube.com/watch?v=FHI4gX5EbYI - 자연어 처리의 단계

- Dialogue System
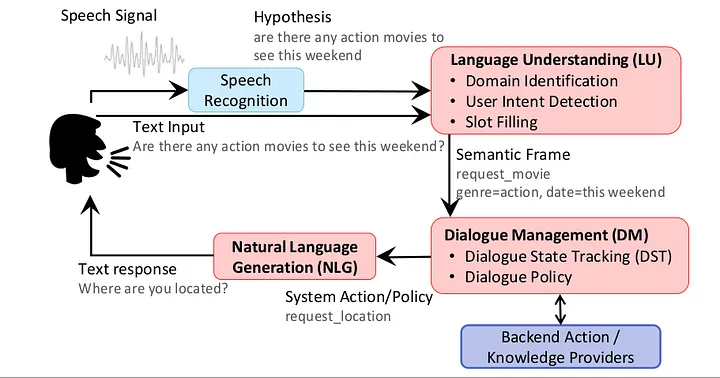
https://medium.com/@nisar.shah1/introduction-to-dialogue-systems-part-1-475a06ab78ad 3. 자연어 전처리에 사용하는 파이썬
3-1. 파이썬 기본 제공
- 파이썬 내장 함수
split 문자열 분리 str.split([sep]) strip 문자열 삭제 str.strip([chars]) join 문자열 연결 str.join(seq) find 문자열 찾기 str.find(search_str, start, end) count 문자열 일치 횟수 반환 str.count(search_str)
str.count(search_str, start)
str.count(search_str, start, end)startswith 문자열이 특정 문자열로 시작하는지 검사 str.startswith(prefix)
str.startswith(prefix, start)
str.startswith(prefix, start, end)endswith 문자열이 특정 문자열로 끝나는지 검사 str.endswith(suffix)
str.endswith(suffix, start)
str.endswith(suffix, start, end)replace 문자열 바꾸기 str.replace(old, new[, count]) lower 소문자로 변경 str.lower() upper 대문자로 변경 str.upper() - 문자열 함수
isalpha() 문자열이 숫자, 특수 문자, 공백이 아닌 문자로 구성되어 있 을 때만 True, 그 밖에는 False 반환 str.isalpha() isdigit() 문자열이 모두 숫자로 구성되어 있을 때만 True, 그 밖에는 False 반환 str.isdigit() isalnum() 문자열이 특수 문자나 공백이 아닌 문자와 숫자로 구성되어 있을 때만 True, 그 밖에는 False 반환 str.isalnum() isspace() 문자열이 모두 공백 문자로 구성되어 있을 때만 True, 그 밖에는 False 반환 str.isspace() isupper() 문자열이 모두 로마자 대문자로 구성되어 있을 때만 True, 그 밖에는 False 반환 str.isupper() islower() 문자열이 모두 로마자 소문자로 구성되어 있을 때만 True, 그 밖에는 False 반환 str.islower() 3-2. 파이썬 re 라이브러리
- 파이썬 re 라이브러리
import re- 정규 표현식(Regular Expression)을 사용해서 입력 문장의 패턴을 찾을 수 있음


3-3. 파이썬 패키지 - NLTK (Natural Language Toolkit)
- 자연어 처리 및 문서분석용 파이썬 패키지(https://www.nltk.org/index.html)
- 분류, 토큰화, 형태소 분석, 태깅, 구문 분석, 의미 추론을 위한 자연어 처리 라이브러리 제공
- WordNet 등 50개 이상의 말뭉치 및 어휘 리소스 제공
- nltk.corpus
– https://www.nltk.org/api/nltk.corpus.html
– http://www.nltk.org/nltk_data/


3-4. 파이썬 패키지 - KoNLPy
- 한국어 정보처리를 위한 파이썬 패키지
- https://konlpy.org/ko/latest/index.html
- 5가지 형태소 분석기를 제공
- Hannanum, Kkma, Komoran, Mecab, Okt

3-5. 파이썬 패키지 - soynlp
- https://github.com/lovit/soynlp
- 한국어 분석을 위한 pure python code
- Noun Extractor, NewsNounExtractor
- Word Extraction
- Tokenizer: Ltokenizer, MaxScoreTokenizer, RegexTokenizer
- Part of Speech Tagger
- Vectorizer
- Normalizer
- Point-wise Mutual Information (PMI)


3-6. 파이썬 패키지 - Gensim
- 토픽 모델링, 문서 인덱싱, 유사성 검색 및 기타 자연어 처리를 위한 오픈 소스 라이브러리
- https://radimrehurek.com/gensim/apiref.html

3-7. 파이썬 패키지 - sklearn
- 머신러닝 및 데이터 전처리를 위한 기능 제공

3-8. 파이썬 패키지 - torchtext

4. 카운트 기반 핵심어 분석
- 핵심어(Keyword)
- 텍스트 자료의 중요한 내용을 압축적으로 제시하는 단어 또는 문구
- 핵심어 분석 방법
- 텍스트에서 많이 등장하는 단어의 등장 빈도를 분석함으로써 핵심어를 추출
- 단순 빈도를 제시하는 방법
- TF-IDF(Term Frequency-Inverse Document Frequency, 어휘 빈도-문서 역빈도)를 계산
- 텍스트에서 많이 등장하는 단어의 등장 빈도를 분석함으로써 핵심어를 추출
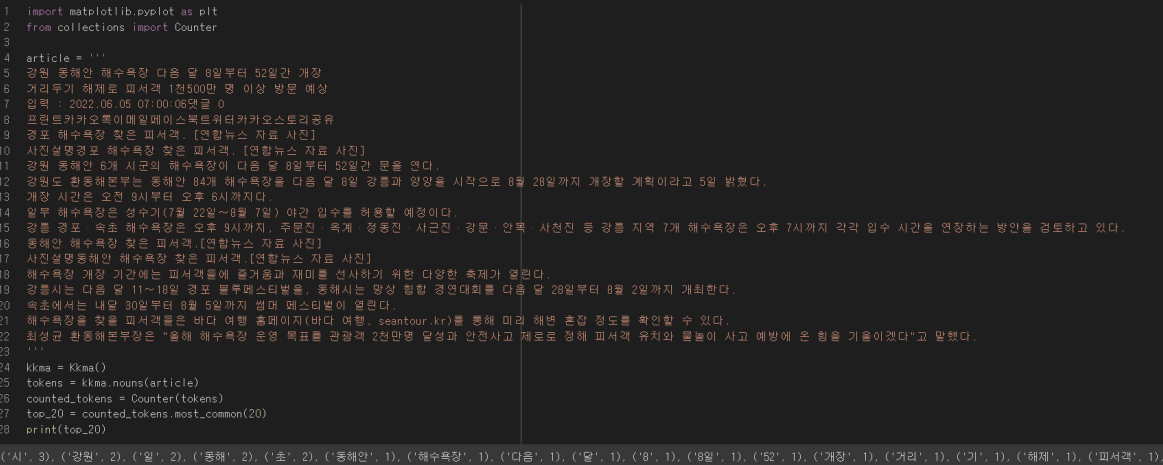
4-1. Counter
4-2. Word Cloud
- 텍스트에 등장하는 단어를 그 등장 빈도에 따라 서로 크기가 다르게 구름형태로 표현
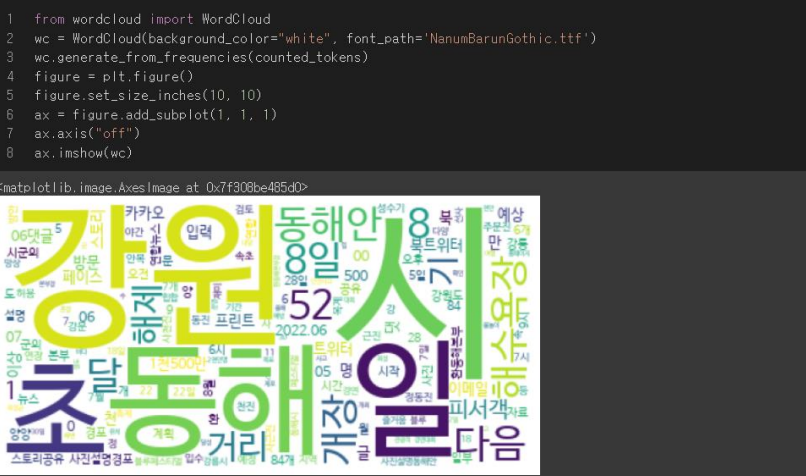

4-3. TF IDF
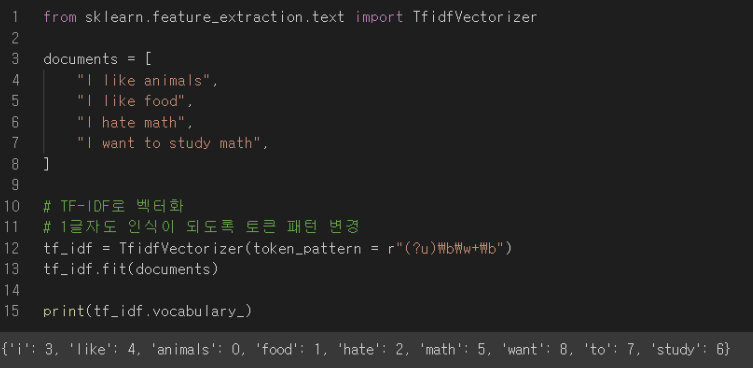

반응형'인공지능 > 인공지능 기초' 카테고리의 다른 글
Auto Encoder, GAN(1) (0) 2024.03.11 NLP (3) (0) 2024.03.10 Embedding (2), NLP (1) (2) 2024.03.08 신경망 성능 향상, 1D conv, Embedding (1) (2) 2024.03.07 VGGNet, GoogLeNet(Inception), ResNet, Transfer Learning (0) 2024.03.06 이전글이 없습니다.댓글