- Auto Encoder, GAN(1)2024년 03월 11일 06시 31분 43초에 업로드 된 글입니다.작성자: 재형이반응형
- 어제 GPT API로 비트코인 자동매매를 만들어보려고 했는데, 생각보다 GPT API 비용이 만만치 않다는 것을 깨달았다
1분마다 보내면 대충 한달에 43만원? - 어제 나도 모르게 급발진해서 바로 11달라 충전하고 10마넌 넣고 그랬는데, 지금 생각해보면 너무 대책 없었던 것 같다
- 이런 것도 다 경험이니까...
- Gemini 오픈 소스를 써볼까
1. Autoencoder

- 입력(𝑥)과 출력(𝑦)이 동일한 차원을 갖는 신경망
- $(x, 𝑦) ∈ ℝ^{d}$
- Encoder의 출력
- $𝑧 = ℎ(𝑥) = 𝑤_{𝑒}𝑥 + 𝑏_{𝑒}$
- Decoder의 출력
- $𝑦 = 𝑔(𝑧) = 𝑔(ℎ(𝑥)) = 𝑤_{𝑑}𝑧 + 𝑏_{𝑑}$
- Loss
- $𝐿(𝑥, 𝑦) = 𝐿(𝑥, 𝑔 (ℎ (𝑥))) = \lVert 𝑥 − 𝑦 \rVert^{2}$
- Autoencoder에서 Encoder는 입력 데이터를 latent vector(efficient code)로 출력하고, Decoder는 입력데이터를 복원하도록 학습한다
- Autoencoder는 비지도 학습 기반의 신경망이다
1-1. VAE (Variational Autoencoder)

- VAE는 generative models의 종류 중 하나이다


- 사진의 각 픽셀의 분포가 정규분포를 따를 때, 뮤 값과 시그마 값을 구해서 Encoder는 입력 데이터를 latent space로 변환하고, Decoder는 입력 데이터와 유사한 형태를 가지는 latent vector를 출력한다
- 즉, 입력값과 비슷한 형태의 출력값을 내보내는 것
- 위에서 입실론은 같은 입력값을 넣었을 때 항상 같은 출력값을 출력하지 못하게 하는 역할을 한다
1-2. Autoencoder 활용
- Image Super Resolution : 저해상도(low resolution) 영상을 고해상도(high resolution) 영상으로 변환하는 작업
- 원본 이미지의 해상도를 낮춘 이미지를 Input으로 사용하고, 원본 이미지를 출력하도록 학습

https://towardsdatascience.com/image-super-resolution-using-convolution-neural-networks-and-auto-encoders-28c9eceadf90 - Image Denosing : 노이징이 있는 이미지를 깨끗하게 변환하는 작업

https://towardsdatascience.com/image-noise-reduction-in-10-minutes-with-convolutional-autoencoders-d16219d2956a 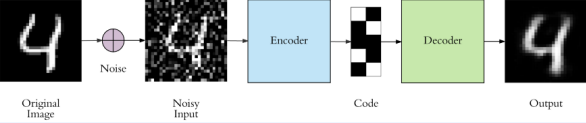

- Anomaly Detection : 이상 현상을 탐지하는 작업

Improving Unsupervised Defect Segmentation by Applying Structural Similarity To Autoencoders, 2019 arXiv - Input으로 정상 데이터를 입력하고 Output으로 정상 데이터와 비슷한 데이터를 출력하게 학습시키면 정상 데이터의 특징을 잘 학습하게 된다
- 이 상태에서 비정상적인 데이터를 입력하게 되면 출력값으로 정상 데이터와 비슷한 데이터를 출력하게 되고 입력값과 출력값의 차이가 생기게 된다 → 이상 현상 탐지

- 학습시킬 때 하나의 인코더와 두개의 디코더를 활용하여 학습시킬 수 있다
- 실제 정답을 인코더에 넣고 나온 값과 디코더1의 출력값의 오차는 최대한 줄이고, 디코더1의 출력값을 다시 인코더에 넣은 값과 디코더2의 오차는 최대한 늘린다. 왜냐하면 디코더1의 출력값은 실제 정답이 아니라 만들어진 가짜 데이터이기 때문이다
2. GAN (Generative Adversarial Networks) 개요
- Generator(생성자)와 Discriminator(판별자)로 구성된다
- Generator(생성자)
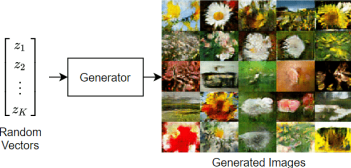
- 입력: 노이즈
- 출력: 가짜 데이터
- Discriminator(판별자)

- 입력: 가짜 데이터 또는 진짜 데이터
- 출력: 진위여부
- 그래서 결국 얻고자 하는 것은 무엇이냐?
- 검정색 : 실제 데이터의 분포
- 초록색: 생성자가 생성한 데이터의 분포
- 파란색: 판별자가 판단하는 값
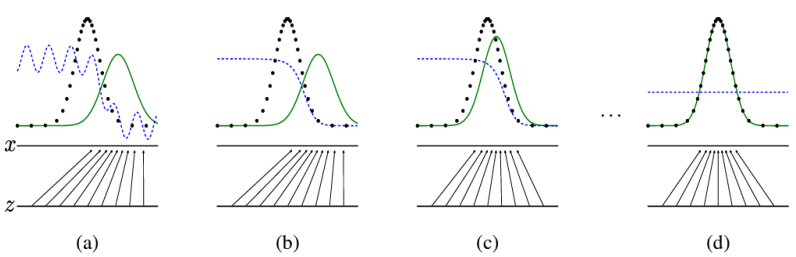
- 초록색과 검정색의 오차를 최대한 줄이고, 파란색은 0.5에 수렴하게 만드는 것이 최종 목표이다
- 이것을 수식으로 표현하면 다음과 같다


- 하지만 GAN은 제대로 학습시키기가 어렵다는 한계가 존재한다. 왜냐하면 생성자와 판별자의 실력이 비슷해야 균형있게 학습이 진행될 수 있는데 그걸 맞추는게 어렵기 때문이다
- 그리고 사용된 생성자의 결과물 형태가 어떠한 과정을 통해 나왔는지 알 수 없었다. 제대로 알지도 못하는데 어떻게 서비스를 운영할 수 있겠는가...
- 그래서 이러한 초기 GAN 모델의 한계를 개선한 모델인 DCGAN과 같은 모델들이 나왔다
다음 이 시간에...
반응형'인공지능 > 인공지능 기초' 카테고리의 다른 글
AI 관련 지식(2) (2) 2024.03.13 GAN(2), AI 관련 지식(1) (0) 2024.03.12 NLP (3) (0) 2024.03.10 NLP (2) (0) 2024.03.09 Embedding (2), NLP (1) (2) 2024.03.08 이전글이 없습니다.댓글 - 어제 GPT API로 비트코인 자동매매를 만들어보려고 했는데, 생각보다 GPT API 비용이 만만치 않다는 것을 깨달았다