인공지능을 공부하면서 나는 어떤 쪽으로 방향을 잡고 깊게 들어갈 것인지를 계속 고민하고 있는데 쉽지 않다
모델을 만든다? 연구? 아니면 만들어진 것을 가져다가 사용하는? 어떻게 사용?
열심히 하는 것도 좋지만 하고 싶은 것이 무엇인지, 무엇이 더욱 미래 가치가 높은지를 충분히 고려한 후에 방향을 잡고 꾸준히 공부하는 것이 중요한 것 같다
1. XAI (eXplainable AI)
https://ex.pegg.io/
XAI란 설명이 가능한 AI를 의미하며 우리가 사용하는 모델들의 결과가 왜 이런 결과를 도출하게 되었는지에 대한 고민을 조금이라도 덜어주기 위한 메뉴얼? 같은 것이다
XAI를 함으로써 Model은 어떤 feature를 가장 중요하게 생각하는지, 각각의 feature가 Model 예측 결과에 어떠한 영향력을 주는지, 각 feature의 일반적인 효과는 어떻게 되는지에 대해 도움을 줄 수 있다
XAI가 필요한 경우는 디버깅을 할 때, 피처 엔지니어링(하나의 피처와 다른 피처를 조합하여 연산하여 새로운 피처를 도출하는 작업을 할 때 인사이트를 줄 수 있음), 데이터 수집을 위한 가이드(가치있고 필요한 데이터만 수집할 수 있음), Model의 예측 결과를 바탕으로 중요 의사결정(model을 실제로 적용하기 위한 판단 근거)을 할 때 사용하면 도움을 받을 수 있다
즉, 한마디로 정리하자면 XAI는 모델의 학습 결과를 해석할 수 있는 방법이다. 모델 성능 개선을 위한 방법을 찾거나 예측 모델을 실제로 사용할 수 있게 하는데(=모델의 신뢰도 상승) 도움을 줄 수 있다
XAI 방법
Interpretable Models – 해석이 가능한 형태의 모델
Model Agnostic – 모델의 종류와 상관없이 해석할 수 있는 방법 (예: SHAP)
Model Specific – 모델 자체의 동작을 바탕으로 해석할 수 있는 방법
Neural Representations – 신경망의 학습 과정에서 추출한 feature의 시각화를 통해 신경망의 학습 내용을 이해
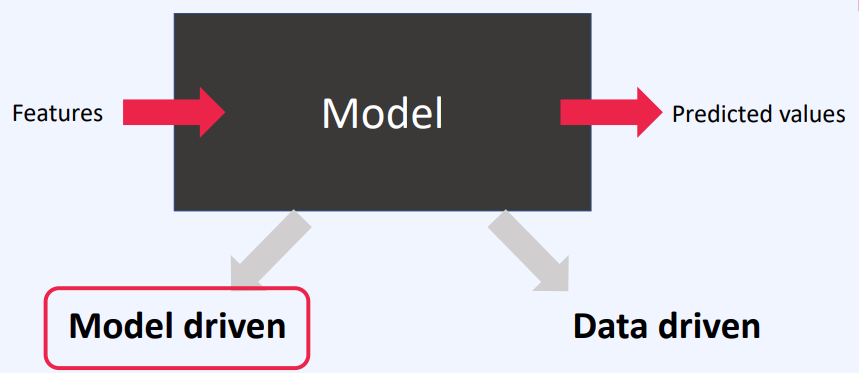
2. Model의 성능 개선 방법 - 신경망 설계 관점 (Model Driven)
2-1. Weight Initialization
초기값을 무엇으로 할 것인지에 따라 모델의 성능이 좌우되기 때문에 잘 선택하는 것이 중요하다
Xavier가 제안한 초기값 고르는 방법, He가 제안한 초기값 고르는 방법들을 사용하자
다행히 pytorch에서는 API 형태로 제공
2-2. Drop Out
학습 중에 은닉층의 뉴런을 무작위로 삭제하여 과적합을 예방하는 기법
p라는 확률로 출력 노드의 신호를 보내다 말다 함
드롭아웃을 적용한 다음에 오는 계층은 앞 계층의 일부 노드들의 신호가 p라는 확률로 단절되기 때문에 훨씬 더 견고하게 신호에 적응
모든 애들을 다 고려해야할 필요가 있을까? 사람도 항상 뇌를 100% 사용하지 않는다! (애초에 100% 사용 못함ㅋ)
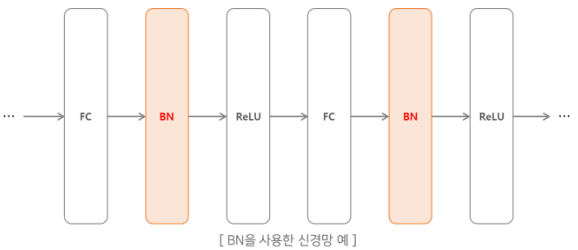
2-3. Batch Normalization
한 번에 입력으로 들어오는 배치 단위로 데이터 분포의 평균이 0, 분산이 1이 되도록 정규화 진행
빠른 학습 가능: learning rate를 높게 잡을 수 있음
자체적인 regularization 효과
데이터들을 어디에 뿌릴지! 데이터들을 얼마나 쎄게 뿌릴지!
Vanishing Gradient 때문에 ReLU를 사용한들 데이터들이 너무 한쪽으로 쏠려있다면 과연 이게 ReLU인지 그냥 Linear인지 알 수 있을까?
2-4. Early Stop
# Train
def traindata(device, model, epochs, optimizer, loss_function, train_loader, valid_loader):
# Early stopping
last_loss = 100
patience = 2
triggertimes = 0
for epoch in range(1, epochs+1):
model.train()
for times, data in enumerate(train_loader, 1):
input, label = data[0].to(device), data[1].to(device)
# Zero the gradients
optimizer.zero_grad()
# Forward and backward propagation
output = model(input.view(input.shape[0], -1))
loss = loss_function(output, label)
loss.backward()
optimizer.step()
# Show progress
if times % 100 == 0 or times == len(train_loader):
print('[{}/{}, {}/{}] loss: {:.8}'.format(epoch, epochs, times, len(train_loader), loss.item()))
# Early stopping
current_loss = validation(model, device, valid_loader, loss_function)
print('The Current Loss:', current_loss)
if current_loss > last_loss:
trigger_times += 1
print('Trigger Times:', trigger_times)
if trigger_times >= patience:
print('Early stopping!\nStart to test process.')
return model
else:
print('trigger times: 0')
trigger_times = 0
last_loss = current_loss
return model